Selle labori käigus liidestame me enda C-keelse programmi SQLite3 andmebaasiga kasutades
libsqlite3-dev teeki. Esimese ülesande käigus alustad andmete lisamisest olemasolevasse andmebaasi, millele järgneb andmete pärimine teise ülesande raames.
Laboril on kaks edasijõudnute ülesannet, millest esimeses muudame andmete lisamist paremaks. Teises ülesandes tuleb uuendad juba andmebaasis olevaid andmeid.
NB! Ülesanne võib osutuda mitte tehtavaks kui andmebaasi fail asetseb P kettal tänu Windows SMBle. Andmebaas jääb lukustatuks ning muudatuste lisamine ei tööta! Lahenduseks on töö ajaks andmebaasifail hoiustada väljaspool P ketast, nt töölaual ning hiljem sinna kopeerida.
Selle ülesande raames harjutad INSERT päringuid andmete lisamiseks. Baasülesanne ei ole vajalik realiseerida C koodis. Kirjuta oma päringud ja jooksuta neid kasutades “Execute SQL” funktsiooni SQLite browser rakenduses.
Nõuded
Kirjuta üles kõik SQL päringud, mida sa jooksutad (nt tavalise tekstidokumendina)! Näita jooksutatud päringuid ning näita oma andmebaasi pärast päringute tegemist. Kokku peab olema 5 päringut!
Tabeli primaarvõtmeks olevaid ID väärtusi
(students.id ,
subjects.id ,
declarations.id ) ei tohi lisamispäringutesse sisse kirjutada! Need teeb andmebaas ise (id atribuut on andmebaasi disainis omadusega auto increment ning kõigi kolme tabeli id atribuudid omavad vastavat generaatorit)
Teosta järgmised andmete lisamise päringud
Lisa andmebaasi enda kui tudengi andmed
Lisa andmebaasi õppeaine, mille oled sooritanud
Lisa endale 3 aine deklaratsiooni. Üks nendest peab olema ainele, mille just lõid, lisaks 2 tk olemasolevatele.
Märkus: hinded ja isikukood ei pea olema reaalsed.
Kui andmed lisatud, näita enda tehtud päringud ning näita oma andmebaasi SQLite Browser rakenduse kaudu.
Ülesanne 2: Andmete pärimine
Selle ülesande raames tuleb sul kirjutada päringuid, millega andmebaasis eksisteerivaid andmeid pärida. Kõik päringud peavad olema kirjutatud C-keelse programmi sisse. Sulle on antud 3 koodinäidet selle lehe alguses materjalide all. Vali, milline neist on sulle kõige arusadavam ning kasuta seda mallina enda päringute kirjutamisel.
Ülesanne on jaotatud kolmeks eraldi hinnatavaks osaks.
Nõuded
Kõik päringud vastavas ülesande osas peavad olema sooritatud. Iga osa hinnatakse eraldi.
Andmed peavad olema täielikult ette valmistatud andmebaasihalduri poolel – st kõik arvutused (nt summa, keskmine, max jne) peavad olema kirjutatud SQL päringu sisse. Arvutusi C koodis ei tohi teha!
Kõik olulised andmeväljad tuleb väljastada. Ära väljasta identifikaatori väärtusi (nt subjects.id, declarations.id)
Päringuid võid jooksutada läbi menüü valikuliselt või ühes rakenduses üksteise järel. Sinu otsustada.
Kõik ressursid peavad olema programmi lõpuks vabastatud – kontrolli lekete puudumist valgrindiga.
Ülesanne 2 hinnatav osa 1 [W14-2]
Esimeses osas teeme lihtsaid SELECT päringuid
Päring 1: Leia kõik õppeained, mis on vähem kui 6 EAPd
Päring 2: Leia kõik õppeaineid, milles on eksam. Järjesta tulemused EAPde arvu alusel vähimast suurimani.
Ülesanne 2 hinnatav osa 2 [W14-3]
Teises osas harjutame veidi keerukamaid SELECT päringuid, kus tuleb kasutada JOIN märksõna ühe- või kahekordselt, et liita mitme tabeli vahelisi andmeid kasutades nende PK-FK võtmepaare.
Päring 1: Leia õppuri ‘Marko’ kõik hinded
Päring 2: Leia kõik õppeaineid, mis sa oled sooritanud. Näita neid koos hinnetega, alustades kõrgeimast hindest.
Ülesanne 2 hinnatav osa 3 [W14-4]
Kolmandas osas harjutame andmete koondamist tunnuste alusel ja tulemuste arvutamist oma SELECT päringutes. Meil on vaja nii JOIN kui GROUP BY märksõnu ning mõningaid arvutamise funktsioone.
Päring: Leia iga tudengi poolt teenitud EAPde arv ning keskmine hinne.
Lisaülesanne 1 [W14-5]: Enda andmebaasi lisamine (usaldusväärsemalt)
Esimese baasülesande raames ei olnud sul otseselt piiranguid, kuidas ennast andmebaasi lisama peaks. Võisid vaadata mis ID väärtused tulid ning neid siis jooksvalt kasutada. Reaalses elus kasutatava andmebaasi puhul päris nii mõistlik teha ei oleks.
Taustinfot
Paremaks lahenduseks pakun välja 2 võimalust. Kummagi puhul pole tegu ideaalse lahendusega, kuid saame sammu võrra paremuse poole.
Võimalus 1a: SQL toetab alampäringuid – me saame ühe päringu sisse peita teise päringu ja selle tulemust siis kasutada esimeses päringus. Näiteks me saame INSERT päringu sisse kirjutada SELECT päringu.
Oletame, et tahame oma näidisandmebaasi lisada isikule Marko Mets veel ühte autot. Selleks saaksime jooksutada järgmise päringu.
Antud näide pole veatu – näiteks kui meil oleks 2 isikut kelle nimi on Marko Mets, siis läheks see katki. Sellest parem versioon on 1b, mille võid esitada laboriülesandena.
Võimalus 1b: Sarnaselt eelmise võimalusega saad teha sarnase päringu eesti isikukoodi põhjal. Tegu ei ole garanteeritult eksisteeriva väärtuse ega ei pruugi ka unikaalsust garanteerida kui välisriigi isikukoodid sekka tuua aga on parem kui eelmine.
Võimalus 2: Parem viis sellele läheneda oleks teha mitu päringut. Esiteks lisaksime end tudengina andmebaasi. Seejärel päriksime andmebaasilt, mis meie ID väärtuseks sai, kasutades
SELECTlast_insert_rowid(); päringut. See annab meile tagasi automaatselt genereeritud ID väärtuse. Seejärel saaksime juba kasutada seda ID väärtust järgnevate andmete lisamiseks
Ka see pole veatu ega ideaalne. Näiteks, kui meie kahe päringu vahel lisatakse mõne teise klientrakenduse poolt uus õppur, siis saaksime tagasi vale koodi (race condition). Seda lahendatakse tegelikus maailmas mehhanismiga TRANSACTION, mis paneb baasi lukku päringute ajaks teistele – ehk siis kõik või mitte midagi meetod. Küll aga kuna meil on kohalik failipõhine andmebaas, siis me saame sellest täna mööda vaadata.
Nõuded
Kirjuta enda andmebaasi lisamise päringud C keelse rakenduse sisse.
Kui lisamise koodi jooksutatakse mitu korda, siis tuleb veenduda, et duplikaate ei tekiks (kontrolli kasutades mõnda teadatuntud unikaalset väärtust – nt kas sinu eID juba eksisteerib).
Pead kasutama automaatselt genereeritud ID väärtusi. Ühtegi ID väärtust ei tohi koodi jäigalt sisse kodeerida.
Kasuta ühte eelnevalt välja pakutud meetoditest.
Lisaülesanne 2 [W14-6] : Olemasolevate andmete muutmine
Andmete muutmiseks andmebaasis saame kasutada UPDATE päringuid. Selliste päringute jaoks peame esmalt tuvastama, millist rida me uuendada soovime ja seejärel saame kirjutada sisse uuendatud väärtused. Oluline on, et tuvastaksime ainult selle või need read, mida me peame uuendama. Ülesande raames pead genereerima kõigile tudengitele Uni-ID tunnused.
Nõuded
Genereeri kõigile tudengitele Uni-ID tunnused
Uni-IDd tuleb lisada andmebaasi kasutades UPDATE lauset. Täita tuleb uni_id atribuut.
Kood peab töötama ükskõik kui paljude tudengite puhul
Kui genereeritav Uni-ID juba eksisteerib, pead tegema konfliktilahendust. Selle jaoks peaksid kirjutama vastava koodi C keeles.
Pärast seda tundi peaksid
Teadma, kuidas andmebaas on defineeritud
Teadma põhilisi andmemudeleid – lameandmebaas ja relatsiooniline mudel
Mõistma seoseid tabelite vahel
Teadma andmebaasihaldussüsteemi (DBMS) eesmärki
mõistma, mida andmebaasihaldussüsteemid teevad
mõistma andmebaasi ja andmebaasihaldussüsteemi erinevust
Ttadma mõningaid laialdaselt kasutatavaid andmebaasihaldussüsteeme
Mõistma SQL-keele põhitõdesid
deklaratiivne keel
süntaks
Oskama kirjutada lihtsaid SQL-päringuid järgmisteks toiminguteks:
andmete pärimine ühest tabelist
andmete ühendamine ja pärimine kahest või enamast tabelist
andmete lisamine tabelisse
Teadma veebipõhiste ja lokaalse andmebaasi eeliseid ja puudusi
Oskama liidestada C programmi SQLite3 andmebaasiga kasutades libsql3 teeki
Teadma, et veebipõhiste SQL-andmebaasidega on võimalik liidestuda vastava andmebaasitüübi teekide abil
Selle labori baasülesande käigus pead looma kaks programmi sama ülesande lahendamiseks ning võrdlema mõlema lähenemise kiirust. Lisaülesande raames tuleb luua kolmas programm ning võrrelda selle jõudlust kahe eelneva.
Labori baasülesande raames on sul tarvis luua kaks programmi. Mõlemad täidavad täpselt sama ülesannet, leides mitu korda iga nimi kordub ette antud andmefailis. Esimese programmi raames pead kasutame lineaarset otsingut koos dünaamilise massiiviga leitavate kirjete hoidmiseks. Teises programmis täidab sama rolli meile kahendotsingpuu.
Esimeses lahenduses kasuta dünaamilist massiivi, mida laiendad jooksvalt
realloc() funktsiooniga.
Teises lahenduses kasuta binaarotsingpuud.
Arvuta programmi siseselt, kui kaua kulus erinevatel etappidel aega
Kasuta etteantud struktuuri ja aja kuvamise funktsiooni, mis on esitatud samm-sammulises juhendis
Tuleb mõõda, kui kaua aega kulus andmete lugemiseks, andmete väljastamiseks, andmete vabastamiseks ning kogu ajakulu
Kuva ekraanil, mitu erinevat nimekombinatsiooni programm leidis, veendu numbri õigsuses.
Optimeeri oma programmi võimalikult palju
Väldi nimekombinatsioonide ekraanile kuvamist – see on aeglane!
Puu loomisel kasuta globaalmuutujat elementide arvu jälgimiseks
Kahendpuu väljastamisel kasuta väljundfaili avamiseks globaalset failiviita, fail ava ja sulge ühekordselt
Hoia nimi struktuuris staatilisena – nt
char combinedName[64]
Labori kaitsmiseks mõtle, kuidas vastaksid küsimustele, mis on esitatud peatükis Programmi tööaja võrdlemine
Programm 1: Lineaarotsing
Alustamiseks tutvu esmalt näidisprogrammiga. Selleks ava
example_linear.c ja
example_linear.h failid ning tutvu nende ülesehitusega, ehita ja käivita see rakendus. See saab olema su aluskood.
Märka, et programm kasutab käsurea argumente – st käivita seda järgnevalt:
./program_name input_file_name
Tutvus tehtud, alustame koodi muutmist enda ülesandele sobivaks.
Praegune versioon faili lugemisest eeldab ühte nime (ühesõnaline). Tunnitöö andmefailis on neli välja rea kohta – eID, first name, last name and city.
Muuda
fscanf() funktsiooni sedasi, et see saaks hakkama täiendavate väljadega. eID ja linna salvestada pole vaja, ülesanne neid ei vaja.
Kleebi nimi kokku kujul
"Eesnimi Perenimi" . Kasuta kleebitud kuju nii otsingufunktsioonis veendumaks, kas tegu on uue nimega või mitte, ning uue nime puhul lisa see oma andmestruktuuri. Vihje:snprintf() on kõige lihtsam viis nime kokku kleepida. Vihje: välja ignoreerimiseks saad kasutada formaati
%*s
Loenda mitu korda nimi esinenud on. Loendamine toimub faili lugemise käigus.
Lisa oma struktuuri kirjeldusse loendur – kasuta kas
int või
unsigned andmetüüpi.
Enne kui hakkad oma loendamist kodeerima, vaata kuidas on näitekoodis lahendatud korduvate (juba massiivis eksisteerivate) nimede tuvastamine. Vihje: Vaata funktsiooni
GetNameIndex() tagastust. Kasuta oma koodis tagastatavat väärtust vajaliku funktsionaalsuse lisamiseks. Funktsiooni
GetNameIndex() ära muuda!
Lisa oma struktuuris paiknevale loendurile algväärtustamine. Seda pead tegema
ReadData() funktsioonis. Mõtle läbi, millal on kõige sobilikum hetk välja algväärtustamiseks.
Lisaks algväärtustamisele peab
ReadData() funktsioonis lahendama loenduri väärtuse suurendamise, kui nimi on varasemalt juba esinenud. Selleks meenuta, mida tagastas
GetNameIndex() funktsioon, kui nimi oli massiivis juba olemas.
Testi esmalt oma koodi ilma valgrindita. Veendu leitud nimede arvus ja väljundfaili tulemustes. Mäluvigade korral on soovitav esimene test teha kasutades LibASANi (address sanitizer), valgrind on aeglane.
Kui funktsionaalselt lahendus töötab, testi oma koodi ka valgrindiga. Valgrindiga jooksutades peab käsureaargument olema pärast programmi nime. Valgrindiga võtab rakenduse testimine üle minuti! valgrind ./example_linear random_people_city_data.txt
Lineaarse algoritmi testimine
Programmi väljundis on oluline jälgida leitud erinevate kombinatsioonide arvu ning programmi erinevateks osadeks kulunud aegu. Erinevate aegade suhtes tuleks kriitiliselt hinnata nende realistlikkust.
Loendamise korrektsuses veendumiseks vaata andmefaili algust. Järgnevalt on esitatud andmefaili esimeste ridade näide.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Anna Martinson 6
Moonika Vares 7
Valeri Teder 5
Liisbeth Sild 7
Anne Koort 5
Marika Koppel 4
Tiit Valk 5
Kerttu Kuusik 10
Maarja Lenk 8
Maris Jalakas 9
Jevgeni Kangro 9
Meelis Tiidus 10
Galina Moroz 6
Oleg Ligi 10
Liis Kuningas 8
...
Kui programm on funktsionaalne, ajad realistlikud ja väljundid korrektsed, testi üle ka valgrindiga veendumaks mäluvigade puudumist. See võib võtta minutike-kaks!
Programm 2: Kahendotsingpuu
Alustuseks ava näiteprogramm
example_bin_search_tree.c ning tutvu selle ülesehitusega. Käivita programm, tutvu selle väljundiga. See saab olema su aluskood.
Märka, et programm kasutab käsurea argumente – st käivita seda järgnevalt:
./program_name input_file_name
Tutvus tehtud, alustame koodi muutmist enda ülesandele sobivaks. Eesmärk on saavutada täpselt sama funktsionaalsus nagu esimese programmiga.
Uuenda struktuuri kirjeldust. Sul on vaja hoida seal nii sõne kui loendurit, täpselt nagu lineaarse otsingu puhul.
Uuenda oma lugemisfunktsioon samal põhimõttel nagu lineaarse otsinguga
Muuda
fscanf() funktsiooni toetamaks failis olevat nelja parameetrit.
Kleebi ees- ja perenimi kokku.
Uuenda lisamise funktsiooni
InsertNode()
Muuda andmetüüpi – näidiskoodis lisatakse puusse täisarv, meie lahenduses tuleb lisada nimi
Muuda võrdlemise operatsiooni sõnedele sobilikuks. Pane tähele, et erinevalt näitekoodist peame meie tuvastama ka olukorra, kui puus nimi juba eksisteerib. Sellisel juhul peame loendurit uuendama.
Uuenda uue tipu loomise funktsiooni
CreateNode()
Muuda parameetrit, et sinna saaks edastada sõne (inimese täisnime)
Lisa struktuuris oleva loenduri (nime korduste arv) algväärtustamine
Uuenda puu väljastamise funktsiooni
PrintTree()
Vii sisse uuendused lähtuvalt muudetud andmestruktuurist
NB! Kuna meie eesmärgiks on kiire programm, siis tuleks failiviit luua globaalse muutujana. Fail ava enne väljastuse funktsiooni väljakutset ning sulge pärast funktsiooni töö lõppu.
Muuda puu läbikäiku. Näitekoodis on puu läbikäiguks valitud eesjärjestus. Leia selline läbikäigu meetod, mille puhul oleks vastus sorteeritud tähestikulises järjekorras. Läbikäigu muutmiseks pead vahetama rekursiivsete kutsete ja praeguse liikme väljastamise järjekorda.
Realiseeri vabastamise funktsioon
Nii nagu kõik puu funktsioonid, peab ka vabastamine olema rekursiivne. Võta inspiratsiooni puu väljastamise funktsioonist. NB! Oluline on valida õige puu läbikäigu meetod (ees-, lõpp- või keskjärjestus). Valesti valitud järjestuse puhul ei ole võimalik puud vabastada.
Lisa aja mõõtmine samamoodi nagu tegime seda lineaarse programmi korral – kõik käsud, andmestruktuur ja väljastus on täpselt samasugused.
Testi oma koodi nii valgrindiga kui ilma. Valgrindiga jooksutades peab käsureaargument olema pärast programmi nime, nt
valgrind ./programm andmefail
Kahendotsingpuu testimine
Testimise jaoks oleme alamosadeks kulunud aja jätnud esitamata, et jätta nende tulemuste hindamine ja võrdlemine lineaarse algoritmiga sinu ülesandeks. See on ka osa ülesande kaitsmisest. Olenemata algoritmist peab leitud nimekombinatsioonide arv olema sama, st 27454.
Küll aga pakume väljavõtet kahendotsingpuu poolt loodavast andmefailist. Võrdle enda andmefaili algust järgneva tulemusega.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Aili Aas 3
Aili Aasa 6
Aili Aavik 6
Aili Allik 4
Aili Allikas 7
Aili Alliksoo 5
Aili Anvelt 10
Aili Arro 7
Aili Aru 5
Aili Aus 3
Aili Hansen 6
Aili Hein 4
Aili Heinsoo 7
Aili Helme 6
...
Programmide tööaja võrdlemine
Nüüd võrdle mõlema programmi ajakulu.
Kumb on kiirem, kumb on aeglasem?
Kas mõned rakenduse alamosad on puu ja lineaarse struktuuri võrdluses ajaliselt märkimisväärselt erinevad?
Kas üks või teine lahendus on läbivalt teisest aeglasem?
Ära unusta iga küsimuse juures ka oma mõttekäike laiendamast!
Mõtle, kuidas võiksid järgnevad muudatused mõjutada programmide tööaega!
Kahendotsingpuu lahendus sisaldab veel ühte täiendavat funktsionaalsust, mida lineaarne otsing ei sisalda. Mis funktsionaalsusega on tegu ning kuidas see mõjutaks lineaarset otsingut täiendavalt?
Kuidas muutuks lineaarse programmi tööaeg, kui muudaksid
realloc() mälu laiendamise strateegia (n + 1) pealt (n * 2) peale.
Kuidas oleksid mõlemad programmid mõjutatud, kui erinevate nimekombinatsioonide arv suureneks märkimisväärselt? Katsu end väljendada Big O notatsiooni kasutades (https://www.bigocheatsheet.com)
Kuidas oleksid mõlemad programmid mõjutatud, kui korduste arvud suureneksid märkimisväärselt, kuid erinevate kirjete arv jääks samaks?
Kuidas mõjutaks puu tasakaalustamine lahendust?
Kas ja mil määral võiks see mõjutada rakenduse töökiirust?
Mis on kõige halvem võimalik olukord tasakaalustamata kahendotsingpuu jaoks?
Kui lahendasid ka lisaülesande, kaasa samasse võrdlusse ka trie andmestruktuur. Kas sellel on ka mõni märkimisväärne eelis tavalise kahendotsingpuu ees?
Lisaülesanne [W13-2]: Trie puu
Loo kolmas programm ning võrdle selle efektiivsust eelneva kahe programmiga. Kasuta kolmandas rakenduses trie andmestruktuuri.
Kõik teised nõuded jäävad samaks.
Soovituslik andmestruktuur
Kasutame muudetud versiooni slaididel olnud näidisest. Asendame struktuuris oleva tõeväärtuse (
isLeaf ), mis näitas sõne lõppu, hoopis täisarvulise väärtusega. Kui väärtus on 0, siis selles asukohas nime lõppu ei ole. Kui väärtus on nullist suurem, siis on tegu lehega, mis tähistab nime. Number ütleb, mitu korda nimi failis eksisteeris.
1
2
3
4
5
6
typedefstructTrieNode
{
charch;
intcount;
structTrieNode *chars[ALPHA_LEN];
}Trie;
Vihje 1: Lisaks tähestikule arvesta ka tühiku ja miinuse sümboliga. Mõlemad neist on olemas andmefailis. Täiendavaid erisümboleid failis ei ole.
Vihje 2: Andmestruktuuri väljade algväärtustamine
CreateNode() funktsioonis on äärmiselt tähtis. Algväärtusta nii loendur kui kogu viitade massiiv.
Pärast seda tundi peaksid
Oskama mõõta rakenduse tööaega programmisiseselt ja süsteemse tööriistaga
Teadma, kuidas seostuvad omavahel kerneli aeg, kasutaja aeg ning reaalne aeg
Teadma, mis võib juhtuda, kui kõik süsteemis töötavad protsessid ei mahu enam arvuti põhimällu ära
Teadma erinevaid kompilaatori optimeerimise tasemeid ning lihtsamal tasemel, mis eeliseid ja probleeme optimeerimine võib tuua
Teadma puudega seotud mõisteid nagu tipp, juur, leht, kõrgus jne
Teadma puu liike ja nendega seotud omadusi (kahendpuu, kahendotsingpuu ning tasakaalustatud kahendpuu)
Teadma erinevaid puu läbikäigu viise (eesjärjestus, keskjärjestus, lõppjärjestus) ning nende kasutusjuhte – st milleks iga läbikäigumeetod sobilik on
Oskama kahendpuu kasutamiseks luua rekursiivseid funktsioone andmete lisamiseks, otsimiseks ja kustutamiseks
Teadma Trie puu omadusi, kasutusvaldkonda ja struktuuri
Loo menüüprogramm, mis kasutab ühesuunalist ahelloendit
Lisatavad elemendid tuleb paigutada loendi algusesse.
Iga elemendi sees on täisarv (id) ja sõne (nimi)
id on automaatselt genereeritud, unikaalne, järjestikuline täisarv, mis algab nullist.
Nimi on sõne, mille sisestab kasutaja uue elemendi loomise käigus
Nime jaoks rakenda dünaamilist mälujaotust vastavalt sisestatava nime pikkusele.
Ülesande lahendamise käigus tuleb sul luua minimaalselt järgnevad funktsioonid:
PrintNode() ,
CreateNode() ,
InsertNode() ,
FindNodeByID() ,
FindNodeByName() ja
Unload() .
Lahendus tuleb luua etteantud aluskoodi peale.
Lahendust luues järgi samm-sammult järgnevat juhendit. Loo funktsioonid vastavalt seal kirjeldatud nõuetele.
Samm-sammuline juhend
NB! Märka, et struktuuri deklareerides on loodud andmetüübile kaks erinevat nime –
struct Node ja
List . Mõlemad tähendavad sama asja – st on aliased (nimekaimud) tänu tüübidefinitsioonile. Kasutuse poole pealt on funktsioonid koostatud sedasi, et
struct Node viitab ühele elemendile, samal ajal kui
List viitab loendile kui tervikule.
1
voidPrintNode(List*pNode);
Esimene funktsioon, mis tuleb luua, on ühe ahelloendi elemendi kõigi liikmete väljastamiseks (st id, nimi ja viit järgnevale elemendile). Funktsiooni prototüüp on juba päisefailis olemas. Sinul tuleb luua funktsiooni keha ja paigutada see koodifaili.
PrintNode() funktsiooni peaksid kasutama iga kord, kui tuleb väljastada ühe elemendi sisu. Sedasi kui loendis olevad liikmed peaksid muutuma, tuleb muudatus väljastuseks teha vaid ühes kohas. Ülesande lõpupoole on sul seda funktsiooni vaja ka nt otsingufunktsioonide tulemuste väljastamiseks.
Kontrolli, et funktsiooni poleks edastatud NULL-viita. NULL-viida puhul väljasta veateade, kehtiva viida puhul väljasta elemendi sisu.
Kommenteeri sisse testimise esimene osa (stage 1) ja jooksuta oma programmi!
NB! Testjuhtudes on sõned kirjutatud UTF-8 vormingus, mis töötab väga kenasti Linuxis, kuid võib tekitada veidi lahkhelisid Windowsi keskkonnas. Probleemide korral muuda sõnesid.
NB! See funktsioon on juba sinu eest valmis tehtud. Pööra tähelepanu funktsioonis oleva tsükli ülesehitusele! Sul on seda vaja loendi läbikäiguks järgnevate funktsioonide lahendamisel.
1
voidPrintList(List*pHead);
Selle funktsiooni eesmärgiks on väljastada kõigi ahelloendis olevate elementide sisu. Funktsioonile
PrintList() edastatakse ahelloendi esimese liikme mäluaadress ning tsükli käigus liigutakse läbi ahelloendi kuni jõutakse loendi lõppu, mida tähistab
NULL -viit.
Funktsioonile võib edastada ka
NULL -viida. See juhtub tavaliselt siis, kui loend, mida väljastatakse, osutub tühjaks.
Funktsioon ise väljastust ei teosta, vaid kasutab selle jaoks eelmises etapis loodud
PrintNode() funktsiooni.
Kommenteeri sisse testimise teine osa (stage 2) ja jooksuta oma programmi!
Seda funktsiooni kasutame uue elemendi loomiseks ja väärtustamiseks. Funktsioon tagastab vastloodud uue elemendi aadressi. Väärtused elemendile antakse kaasa parameetritena.
Loo ja anna mälu uuele elemendile
Määra ära ID väärtus (järjestikuline suurenev täisarv, kasuta
static märksõna)
Küsi mälu ja kopeeri struktuuri nimi
Väärtusta
pNext viit
Tagasta struktuur
NB! Siin funktsioonis on kahel korral vaja mälu anda. Mõlemat tagastust tuleb kontrollida! Vea korral tagasta NULL-viit! Programm peab vea korral jätkama töötamist.
Kommenteeri sisse testimise kolmas osa (stage 3) ja jooksuta oma programmi! Ainukesed visuaalselt nähtavad erinevused on aadressiruumi muutus elementidel (läksime funktsioonide pinust kuhja). Valgrindiga käivitades näed mälu küsimiste arvu suurenemist!
Selle funktsiooni eesmärgiks on lisada eelmise funktsiooni poolt loodud uus element
pNode ahelloendisse, millele viitab
ppHead . Topeltviit on vajalik, et lisada uus element loendi algusesse.
Baasülesandes lisame uue elemendi loendi algusesse. Selleks on vaja ainult 2 omistuslauset kirjutada!
NB! Enne lisamist kontrolli, et
pNode poleks
NULL -viit!
Kommenteeri sisse testimise neljas osa (stage 4) ja jooksuta oma programmi! Visuaalselt väljundis midagi ei muutu võrreldes eelmise korraga.
Seda funktsiooni kutsutakse hävitajaks (destructor), mille eesmärk on andmestruktuur mälust vabastada. Vabastamise käigus vabastatakse ka struktuuri liikmed, mis on dünaamiliselt loodud – meie puhul on selleks nimi.
Ahelloendi vabastamiseks on vaja tsüklis käia läbi kogu loend. Läbikäigu ideega tutvu
PrintList() funktsioonis.
Loendi vabastamise juures on oluline pöörata tähelepanu praeguse elemendi vabastamisele. Nimelt pärast praeguse elemendi vabastamist ei ole meil enam ligipääsu selle
pNext viidale. Sellest tingitult on meil vaja vabastamiseks täiendavat abiviita praegusele elemendile, mis teeb selle protseduuri natuke keerukamaks.
Tsüklis on 3 olulist sammu. Kõige elegantsema tsükli saad kasutades
while() tüüpi tsüklit!
Praeguse elemendi aadressist koopia tegemine (seda koopiat kasutame vabastamiseks)
Järgmise elemendi juurde liikumine (
pCurrent = pCurrent->pNext )
Praeguse elemendi ja selle liikmete vabastamine.
Kommenteeri sisse testimise viies osa (stage 5). Jooksuta programmi kasutades valgrindi! Peaksid nägema, et rakendus on 6 korda mälu küsinud ning vabastanud.
==17208== All heap blocks were freed -- no leaks are possible
==17208==
==17208== For lists of detected and suppressed errors, rerun with: -s
==17208== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
1
structNode*FindNodeByName(List*pHead,char*name);
1
structNode*FindNodeByID(List*pHead,intid);
Selles osas loome kaks otsingufunktsiooni, millest üks otsib nime ja teine ID väärtuse järgi. Kui otsing annab tulemuse (st loendis on selline element), tagastatakse viit leitud elemendile. Kui elementi loendis ei ole, tagastatakse NULL-viit.
Kasuta
PrintNode() funktsiooni leitud elemendi väljastamiseks.
Kommenteeri sisse testimise viiesosa (kuues 6) ja jooksuta oma programmi! Märka, et näidisväljundis on veateade väljastatud PrintNode() poolt ja ei ole seotud otsinguga!
Palju õnne! Kõik baasfunktsionaalsuseks vajaminevad funktsioonid on nüüd valmis! Nüüd lisa abifunktsioonid ja koodilaused, et rakendus oleks kasutatav läbi menüü. Testimiseks mõeldud koodi võid soovi korral oma rakendusest kustutada.
Lisada tuleks näiteks nime küsimine uue kirje loomisel või otsitava sisestused otsingufunktsioonide kasutamiseks ning vajadusel tagastuste töötlemiseks. Kui valmis, anna märku tunnitöö esitamiseks!
==17678== All heap blocks were freed -- no leaks are possible
==17678==
==17678== For lists of detected and suppressed errors, rerun with: -s
==17678== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
Lisaülesanne 1 [W12-2]: Tähestikulises järjestikus sorteeritud loend
Selle ülesandega muudame oma elementide lisamise funktsiooni selliseks, et loend oleks alati sorteeritud tähestikulises järjekorras
Nõuded
Uuenda
InsertNode() funktsiooni sedasi, et uus element paigutataks loendis olevate elementide vahele sedasi, et loend oleks tähestikulises järjekorras
Selleks pead toetama elemendi lisamist loendi algusesse, lõppu või keskele
Uuenda
FindNodeByName() funktsiooni, et see lõikaks kasu tähestikulisest järjekorrast.
Kui oled varasemalt lahendanud esimese lisaülesande, siis uuenda ka eemaldamise funktsiooni, et ka see lõikaks kasu tähestikulisest järjekorrast.
Märkused
Vastavalt loendi asukohale, kuhu element lisatakse, tuleb viitasid käidelda erinevalt.
Veendu asukohas enne lisamise alustamist!
Lisaülesanne 2 [W12-3]: Elementide eemaldamine
Loo kaks funktsiooni elementide eemaldamiseks loendist vastavalt nime või ID alusel.
Nõuded
Realiseeri
RemoveNodeByName() funktsioon, mis eemaldab elemendi nimelise vaste korral.
Realiseeri
RemoveNodeByID() funktsioon, mis eemaldab elemendi ID vaste korra.
Võimalusel kasuta ära omadust, et loend on juba sorteeritud tähestikulises järjekorras (lisaülesanne 1)
Veendu loendi terviklikkuses pärast elemendi eemaldamist. Testi loendi keskelt, algusest ja lõpust!
Märkused
Esmalt leia, kas element, mida peaksid eemaldama, üldsegi eksisteerib
Eemaldamisel ühesuunalisest loendist on sul vaja meeles pidada eelmise elemendi asukohta! Seetõttu ei saa sa korduvkasutada
FindNodeBy() funktsioone! (Saaksid, kui see oleks kahesuunaline ahelloend).
Algusest, keskelt ja lõpust eemaldamine on erinev! Kontrolli positsiooni enne eemaldamise alustamist, seejärel vali sobilik eemaldamise meetod.
Ära unusta mälu vabastada!
Topeltviit on vajalik loendi algusest eemaldamiseks.
Pärast seda tundi peaksid
Teadma ühe- ja kahesuunalise ahelloendi omadusi
Teadma, kuidas tähistatakse ahelloendi lõppu
Mõistma loendite eeliseid ja puudujääke
Teadma erinevate operatsioonide keerukust ahelloendil ning erinevusi keerukusel massiiviga võrreldes
Oskama ahelloendit luua, läbi käia ning vabastada
Oskama ahelloendisse elemente lisada algusse, lõppu ning vahepeale
Teadma, kuidas töötavad funktsioonides
static märksõnaga deklareeritud muutujad ning millises mälualas need paiknevad
Selles praktikumis on kaks baasülesannet, üks iseseisev lisaülesanne rekursioonile ning üks lisaülesanne, mis laiendab pinu baasülesannet.
Tunnis vajaminev teooria esitatakse kahes osas, teine pool teooriast esitatakse pärast mõne aja möödumist.
Ülesanne 1 [W11-1]: Rekursiooni ülesannete komplekt
Esimese ülesande raames tuleb sul luua kolm rekursiivset programmi (osa 1, 2 ja 3). Ülesannet saab esitada ainult siis, kui kõik kolm on valmis!
NB! Tegu on äärmiselt lihtsate ülesannetega, väldi internetist lahenduste otsimist!
Tunni alguses luuakse näidislahendus faktoriaali rekursiivsest lahendamisest!
Nõuded
Võid laheduse luua ühe failina, kus on kolm rekursiooni korraga, või kolme erineva programmina. Näited on tehtud kolme erineva rakendusena.
Kõigil juhtudel on kohustuslik toetada sisendina positiivset täisarvu. Negatiivse sisendi korral on kas lahenduses märgitud eraldi vastus (baasjuht) või tuleb kuvada viga.
Sisendi võid küsida rakenduse sees või lugeda käsurea argumendina.
Iteratiivseid lahendusi kasutada ei tohi, kõik kolm osa peavad olema lahendatud rekursiivselt.
Esitada saab ülesannet vaid siis, kui kõik kolm osa on valmis.
Programm 1: summa
Loo rakendus, mis leiab kõigi positiivsete täisarvude summa kuni kasutaja sisestatud arvuni. Negatiivse argumendi korral rekursiivsele summa funktsioonile on summa 0 (positiivsed arvud puuduvad, baasjuht).
Loo rakendus, mis leiab soovitud Fibonacci arvu. n-indaks fibonacci arvuks on selle kahe eelneva Fibonacci arvu summa ehk siis fibx = fibx – 1 + fibx – 2. Erinevalt eelnevatest rekursioonidest on Fibonacci jadal kaks seetõttu ka 2 baasjuhtu.
Märkasid kui kaua aega läks viimase leidmiseks? See on ootuspärane ning parandada vaja ei ole, kuid oluline on just aru saada miks see nii kaua aega võttis!
Kõik kolm programmi valmis, näita nüüd ülesanne ette!
Programmi ajakulu saad mõõta kasutades
time programmi. Siin on võrdluseks kaks erinevat rekursiivset lahendust samast programmist. Teisel juhul on kasutatud lähenemist, mida kutsutakse tail-recursion’iks ehk sabarekursiooniks. Selle kohta võid vajadusel uurida omal käel.
1
2
3
4
5
6
7
8
9
10
11
12
risto@risto-tux:~/Nextcloud/prog2/wk10_recursion_stack$ time ./fib 45
Selles ülesandes loome menüüprogrammi, mille sisuks on demonstreerida pinu funktsioone. Tunnis lahendatav ülesanne on demonstratiivne ning toetab varasemalt õpitud dünaamilist mälu – selline lahendus ei too oma keerukuse tõttu välja pinu eeliseid kiiruses!
Tunni alguses luuakse osaline näidis, kus lahendame ära Push() funktsiooni!
Nõuded
Loo oma rakendusele menüü struktuur – kasutaja peab saama valida, millist operatsiooni soovib teostada
Loo
Pop() ja
Peek() funktsioonid
Pop() eemaldab pealmise elemendi pinust ja tagastab selle väärtuse.
Peek() tagastab pealmise elemendi, kuid ei eemalda seda
Loodavad funktsioonid elementide väärtusi kuvada ei tohi! Ekraanile kuvatakse väärtused pärast menüüsse tagastamist!
NB! Baasversioonis on lubatud reserveerida üks väärtus tähistamaks pinu alatäitumist, et väljastuses illegaalset väärtust ei kuvataks. Lisaülesande esitamisel see lubatud ei ole.
Vastavalt funktsioonile veendu, et oleksid realiseeritud kas ala- või ületäitumise kontrollid.
Pööra tähelepanu olukorrale, kus pinust eemaldatakse kõik elemendid –
realloc() funktsiooniga 0 baiti küsida ei tohi, tuleb kasutada
free() funktsiooni!
Pinu silumisfunktsioon
Selleks, et saaksid paremat aimu pinu sisust, pakun sulle ka silumisfunktsiooni. Tegelikus olukorras sellist funktsiooni sageli rakendada ei saaks, kuna see võib olla vastuolus pinu piirangute ning ka konkreetse pinu realisatsiooniga!.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
voiddebug_stack(stack st)
{
printf("DEBUG\n");
printf("\tStack size: %d\n",st.size);
printf("\tData pointer: %p\n",st.data);
if(st.size!=0&&st.data==NULL)
{
printf("Sanity check failed!\n");
printf("Stack is NULL, but size is not 0\n");
return;
}
if(st.size==0&&st.data!=NULL)
{
printf("Sanity check failed!\n");
printf("Stack data is not NULL, but size is 0\n");
return;
}
printf("\tValues: ");
for(inti=st.size-1;i>=0;i--)
{
printf("%d ",st.data[i]);
}
printf("\n\n");
}
Testimine
Testimisel pööra tähelepanu järgnevale:
pinu ületäitumine
pinu alatäitumine
pinu andmete vabastamine pärast viimase elemendi kustutamist (valgrind!)
Mälulekke ohule, kui programm suletakse hetkel, kui pinus on veel andmeid (valgrind!)
käesolev lisaülesanne on sulle antud ingliskeelse algoritmi kirjeldusena. Tegu on täiesti eraldiseisva ülesandega, mis ei ole seotud eelnevalt tehtud tunnitöö lahendusega!
NB! Olulised muutujad on antud matemaatikutele omases kirjapildis ehk üksikute tähtedena – soovitus oma programmis kasuta pikemaid ja selgitavamaid nimesid nagu on programmeerimises omane.
Given search key
K and an array
A of
n integers A0, A1, … , An – 1 sorted such that A0 ≤ A1≤ … ≤ An – 1 use the following algorithm to find if
K ∈ A
Set lowIndexL to
0 and highIndex H to
n − 1 .
Call the recursive function using 4 arguments –
A, L, H, K .
If
L > H , the search terminates as unsuccessful – return 0
Set
m (the position of the middle element) to the
floor of (L + H) / 2
If Am < K, set
L to
m + 1 , call recursion again
If Am > K, set
H to
m − 1 , call recursion again
If Am = K, the search was successful – return 1
Ülesanne valmis, valmista enne esitamist ette vastused järgmistele küsimustele. Kui vastused olemas, anna märku!
Ajaline keerukus – võrdle antud algoritmi ja tavalist lineaarset otsingut. Mitu võrdlust läheks vaja, et võrrelda massiivi, kus on
16 liiget
256 liiget
100 000 liiget
Anna hinnang algoritmi keerukusele – nt konstantne, logaritmiline, lineaarne, eksponentsiaalne (https://www.bigocheatsheet.com)
Kui massiiv poleks sorteeritud, kas see algoritm töötaks?
Lisaülesanne 2 [W11-4]: pinu laiendus
Selles ülesandes loome paar lisavõimalust oma pinule ning teeme seda veidi universaalsemaks.
Nõuded
Lisa oma pinule järgmised funktsioonid
Duplicate()
Swap()
Need funktsioonid tohivad kasutada ainult Push() ja Pop() funktsioonide väljakutseid!
Muuda oma Pop() ja Peek() funktsioonide kujusid sedasi, et kehtiksid järgmised nõuded
Pinu peab toetama kõiki arve (ei tohi olla reserveeritud mitmetähenduslike väärtusi).
Juhul kui tekib pinu alatäitumine, siis kuvatakse vaid veateade, väärtust ennast ei kuvata
Märkus: Lisafunktsioonide jaoks pead suure tõenäousega muutma ka Push() funktsiooni!
Testimine
Olulised kitsaskohad, mida testida (lisaks tavaolukordadele)
Pop(), kui pinu on tühi (ei tohi numbrit väljastada)
Selles tunnis on üks ülesanne, mida laiendab kaks lisaülesannet
Ülesanne [W08-1]: Faili lugemine kasutades dünaamilist mälu
Selle ülesande eesmärgiks on tutvuda, kuidas lugeda teadmata pikkusega faile sedasi, et me kasutame täpselt nii palju mälu, kui failis olevate andmete hoiustamiseks vaja on.
Andmefail
Andmefaili struktuur on järgnev:
<indeks> <perenimi> <eesnimi> <õppekava kood> <punktide arv>
Indeks (täisarv)
Ees- ja perenimi – erineva pikkusega sõned
Õppekava kood – 4-tähemärgi pikkune sõne
Punktide arv – kümnendmurd vahemikus 10,0 kuni 30,0 täpsusega 0,1.
Võid kasutada andmefailide loomiseks oma eelmise nädala praktikumiülesande lahendust. Testimiseks on antud siiski kindlad failid, et saaksid oma väljundit võrrelda.
Lugemiseks kasuta
realloc() funktsiooni, laiendades mäluala suurust jooksvalt lugemise käigus.
Andmed salvesta dünaamiliselt loodud struktuurimassiivi
Lugemise lõpuks peab küsitud mälumaht olema täpselt nii suur, kui on vaja failis olevate andmete hoiustamiseks.
Faili tohib vaid ühel korral lugeda (korduv lugemine keelatud! Ka lihtsalt reavahetuste arvu lugemine ei ole lubatud!)
Arvesta, et faili pikkus võib muutuda! St faili pikkus selgub lugemise käigus!
Kõik muutuva pikkusega sõned tuleb mälus hoida täpse pikkusega.
Lugemise ajal kasuta staatilist puhvrit, struktuuris hoidmiseks kasuta dünaamilist mälu!
Failis on stipendiumile kandideerivate tudengite loetelu. Stipendiumi saavad:
Igast järgnevast erialast kuni 7 kõige kõrgema punktisummaga tudengit: IACB, EARB ja MVEB.
Kuva stipendiumi saajate nimekiri ning näita mitu tudengit igalt erialalt stipendiumi sai.
Veendu, et programm ei tekita mälulekkeid!
Andmestruktuur ülesandele
Selles ülesandes läheme üle dünaamilisele mälule struktuuri liikmete hulgas, mille pikkus on muutuv (sõned ja teised massiivid) – see säästab mälu ja suurendab paindlikkust. Struktuur võtab järgneva kuju:
1
2
3
4
5
6
7
8
typedefstruct
{
intindex;
char*fName;
char*lName;
charcurriculum[LEN_CURRICULUM+1];
floatpoints;
}Person;
Märkused:
Soovi korral võid nimetusi endale sobilikumaks muuta
fName ja
lName on nüüd viidad, mis vajavad dünaamilist mälu, enne kui nendesse midagi salvestada saab – seda kuna nime pikkus on muutuv inimeselt inimesele.
Õppekava koodi massiiv on staatiline, sest see on alati täpselt sama pikk – dünaamiline mälu siin oleks raiskav.
Üksikud täisarvud, murdarvud jne jäävad samuti staatiliseks – jällegi, dünaamiline mälu siin teeks programmi põhjendamatult aeglasemaks ja keerukamaks.
Soovituslik loetelu funktsioonidest
NB! Funktsioonide tegelik kuju sõltub, kuidas otsustad ülesannet lahendada ja struktureerida.
Minimaalselt on sul vaja kolme funktsiooni:
Andmete lugemise funktsioon failist (vali välja järgmisest peatükist).
Vastuste väljastamise funktsiooni.
1
2
voidPrintScholarships(Person*pStudents,intn);// Good for base task
voidPrintScholarships(StudentWrapper stdWrapper);// Good for advanced task 2
Andmete vabastamise funktsiooni
1
2
3
voidFreeStudentData(Person*pStudents,intn);// Good for base task
voidFreeStudentData(Person**ppStudents,intn);// Good for base task with defensive programming
voidFreeStudentData(StudentWrapper stdWrapper);// Good for advanced task 2
Soovituslikud funktsioonid enda elu lihtsamaks tegemiseks
Ühe tudengi andmete printimise funktsioon (kasulik kui prindid tudengi andmeid, kes stipendiumi saab.
1
voidPrintStudent(Student*s);
Kaitsva programmeerimisstiili jaoks kulub ära ka slaididel näidatud vabastamisfunktsioon
1
voidFreeMemory(void**p);
Lugemise kontrollimiseks võib olla mõistlik luua ka funktsioon, mis trükib kõigi tudengite andmed välja, mis failist kätte saadi. See aga pole ülesande osa.
Funktsioon andmete lugemiseks
Sel korral võtab andmete lugemise funktsioon veidi teistsuguse kuju. Funktsioonist on meil vaja saada kätte 2 uut väärtust – dünaamilise massiivi asukoht ja failist loetud ridade arv. Selleks pakun välja kolm erinevat funktsiooni kuju, mille hulgast saad valida endale meelepärase!
Variant 1 on kõige sarnasem varasemalt tuttavale faili lugemise funktsiooni kujule. Funktsiooni tagastuseks on ridade arv ning mäluviida saame kätte kasutades topeltviita.
Variant 2 vahetab andmete liikumise ümber – ridade arv tuleb nüüd kasutades viita ning tagastusena anname mäluaadressi dünaamilisele massiivile. Sedasi saab vältida topeltviida kasutamist, kui see liiga keerukaks osutub.
Variant 3 liigutab kogu andmevahetuse viitadele. See lubab meil funktsioonist tagastada funktsiooni töö oleku – st kas lugemine töötas edukalt või ebaõnnestus. See on ka kõige lähedasem suurele osale C keelsetele funktsioonidele – suur osa neist tagastab nulli, kui töö oli edukas, ning mittenullise väärtuse, kui juhtus viga.
NB! Kasutades lisaülesandes 2 tutvustatud ümbrisstruktuuri ideed saab parameetrite loetelu veelgi puhtamaks!
Variant 1Variant 2Variant 3
C
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
/**
* Description: Reads data from a file. During reading, a dynamic
* struct array will be created and expanded using realloc()
* Parameters: ppStudentData - Stores the location of the allocated array
* fileName - name of the input file to read
* Return: Number of lines read from the file
*/
intReadData(Person**ppStudentData,char*fileName)
{
// Current line counter
intcount=0;
// Main pointer for the allocated array
Person*pData=NULL;
// Declare temporary buffers for reading (all variables you intend to read!)
// Read a record at a time in a loop into buffer(s)
while()
{
// Rellocate memory to fit the latest line, using a temporary variable
Person*pTemp=realloc(pData,/* Calculate number of bytes required */);
// Check allocation was successful
if(pTemp==NULL)
{
/* Write error behavior here */
}
// Allocation success, make sure both pointers point at memory
pData=pTemp;
// 1. Allocate all dynamic buffers (strings in this task)
// 2. Copy the data from buffers to struct array
// Increment number of records successfully read
count++;
}
// Store the allocated array trough the double pointer
*ppStudentData=pData;
// Return the number of lines read
returncount;
}
C
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
/**
* Description: Reads data from a file. During this, a dynamic
* struct array will be created and expanded using realloc()
* Parameters: pLineCount - pointer to store the read line count
* fileName - name of the input file to read
* Return: Pointer to the allocated data array
*/
Person*ReadData(int*pLineCount,char*fileName)
{
// Current line counter
intcount=0;
// Main pointer for the allocated array
Person*pData=NULL;
// Declare temporary buffers for reading (all variables you intend to read!)
// Read a record at a time in a loop into buffer(s)
while()
{
// Rellocate memory to fit the latest line, using a temporary variable
Person*pTemp=realloc(pData,/* Calculate number of bytes required */);
// Check allocation was successful
if(pTemp==NULL)
{
/* Write error behavior here */
}
// Allocation success, make sure both pointers point at memory
pData=pTemp;
// 1. Allocate all dynamic buffers (strings in this task)
// 2. Copy the data from buffers to struct array
// Increment number of records successfully read
count++;
}
// Store the number of lines trough the pointer
*pLineCount=count;
// Return the pointer to the data
returnpData;
}
C
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
/**
* Description: Read data from a file. During this, a dynamic
* struct array will be created and expanded using realloc()
* Parameters: ppStudentData - Stores the location of the allocated array
* pLineCount - pointer to store the read line count
==14397== All heap blocks were freed -- no leaks are possible
==14397==
==14397== For lists of detected and suppressed errors, rerun with: -s
==14397== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
Lisaülesanne 1 [W08-2]: Optimaalne mäluhõive
Selles ülesandes muudame oma dünaamilise mälu hõivamise mõistlikumaks kasutades optimaalsemat mälu laiendamise strateegiat.
Nõuded
Muuda oma faili lugemist sedasi, et lugemiseks kasutaksid (n * 2) strateegiat
St iga kord kui küsitud mälumaht saab otsa, laiendatakse mäluala 2x võrreldes olemasolevaga
Alustamiseks vali n, mis on suurem kui 1 (vali siiski vähemalt 3x väiksem kui pikima faili pikkus)
Lisaülesanne 2 [W08-3]: ümbris-struktuur
Selles ülesandes muudame oma koodi veelgi loetavamaks ja seotumaks, pannes oma andmestruktuuri ja selle omadused ühte ümbritsevasse struktuuri.
Nõuded
Pane oma struktuurimassiiv teise struktuuri ehk ümbrise sisse (wrapper struct),
Ümbrises peaks olema 3 muutujat – viide struktuurile, struktuuri suurus ja struktuuri kasutatud liikmete arv.
Muuda oma funktsioonide parameetreid nii, et nüüd need kasutaksid uut vastloodud ümbrisstruktuuri.
NB! Mõtle läbi, mis funktsiooni on mõistlik viit ümbrisele anda, millisesse pole seda mõtet teha!
Vihje: Kuna nüüd on iga välja poole pöördumisel vaja ümbrisstrukuturist valida välja õige liige, siis võib loetavuse huvides olla see mõistlik “lahti pakkida” eraldi muutujasse vastava funktsiooni või tsükli sees. Näiteks
1
2
3
4
5
6
7
8
9
10
voidPrintData(StudentWrapper stdWrap)
{
intlen=stdWrap.used;
for(inti=0;i<len;i++)
{
student*s=&stdWrap.studentDB[i];
}
}
Pärast seda tundi peaksid
teadma erinevaid võimalusi, kuidas struktureerida ja lugeda faile, mille pikkus võib erineda
oskama dünaamiliselt oma massiivide suurust muuta
oskama lugeda faile dünaamilist mälu kasutades jooksvalt ja täpselt
teadma kõiki võimalike realloci tagastuste võimalus
teadma kahte laiendamise strateegiat (n + 1) ja (n * 2) ning oskama neid kahte võrrelda
oskama struktuuri liikmetele mälu küsida
teadma ja oskama rakendada ohutu programmeerimise tehnikat mälu vabastamisel.
teadma kõiki samme, mida strdup() funktsioon taustal teeb
Selle praktikumi ülesandeks on luua juhuandmete generaator. Ülesannet laiendab kaks lisaülesannet.
Ülesanne [W07-1]: Juhuandmete generaator
Praktikumiülesandeks on koostada juhuandmetega andmefaili generaator. Selliseid generaatoreid kasutatakse sageli rakenduste testimiseks enne, kui saadakse ligipääs reaalsetele andmetele. Päris mitmetes selle kursuse praktikumiülesandes on testandmed genereeritud sarnasel viisil.
NB! Kuigi üks soovituslikest juhuandmete genereerimise viisidest on kasutada tehisaru, siis alati ei tööta see just kuigi hästi või osutub absurdselt kalliks – nt kui soovid genereerida miljoneid ridu keerukaid andmeid.
Indeks on unikaalne täisarv. Esimese kirje indeks on 0, igal järgneval suureneb see 1 võrra.
Veendu, et kogu mälu on programmi lõppedes vabastatud kasutades Valgrind’i
Töövoog
Loo vajalik struktuuri kirjeldus, salvesta see päisefaili
Küsi kasutajalt mitu kirjet tuleks genereerida
Küsi mälu vajalike kirjete hoidmiseks. Kontrolli, et mälu saadi!
Genereeri vajalikud kirjed
Iga isiku jaoks pead genereerima kõik väljad juhuslikult
Eesnimi, perenimi ja õppekavakood tuleb juhuslikult valida olemasolevatest valimitest. Selleks pead genereerima täisarvu (nt mitmes eesnimi valimist) Vihje: Sa võid nime kas kopeerida enda struktuuri või hoiustada vaid viita nimele
Genereeri vastuvõtupunktid (10,0 <= punktid <= 30,0 täpsusega 0,1) Vihje: Mõtle matemaatilistele omadustele – nt mis vahe on 30 ja 300!? rand() funktsioon tagastab alati täisarvu ning seda muuta ei saa.
Sorteeri massiiv
Mõtle ka miks on siin halb idee kasutada eksponentsiaalse keerukuse kasvuga meetodeid (bubble/insertion/selection)
Kirjuta andmed väljundfaili
Vabasta mälu
Kontrolli oma rakendust kasutades valgrindi! Seda mitte ainult lõpus, vaid ka siis, kui rakendus käitub imelikult või jookseb kokku!
Qsordi võrdlusfunktsioon
Pakun välja kaks erinevat võrdlusfunktsiooni võimalust. Vali see millest saad paremini aru, või kirjuta enda lahendus.
Esimene näide kasutab tüübiteisendusi jooksvalt, vältides lisamuutujate loomise vajadust.
==12389== All heap blocks were freed -- no leaks are possible
==12389==
==12389== For lists of detected and suppressed errors, rerun with: -s
==12389== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
Kontrolli oma väljundfaili ning veendu tulemuste korrektsuses. Sinu väljundfail saab olema erinev, andmed on juhuslikult genereeritud.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
0 Aas Heidy IACB 27.9
1 Aas Juhan IACB 29.6
2 Aas Reet IACB 18.2
3 Aasa Anne EARB 10.1
4 Aasa Julia MVEB 13.8
5 Aasa Sven EARB 14.5
6 Aasa Taavi MVEB 16.1
7 Aasa Urve EARB 29.4
8 Aasa Valdo IACB 21.2
9 Allik Ivari IACB 21.3
10 Allik Kerttu MVEB 29.8
11 Allik Kerttu MVEB 21.4
12 Allik Laivi MVEB 24.2
13 Allik Peeter IACB 22.3
14 Allik Rainer IACB 17.5
Lisaülesanne 1 [W07-2]: Väljundfaili formaat
Esimese lisaülesande käigus lisad oma lahendusele CSV formaadi toe. Kasutaja saab valida sobiva väljundformaadi – kas tühikutega või komadega eraldatud väljundfail.
Nõuded
Lisa oma programmile võimekus genereerida andmeid CSV formaadis
Esimene rida CSV failis peab olema päis, mis sisaldab genereeritud andmeväljade nimetusi
Sellele järgnevad genereeritud andmeread. Iga andmeväli peab olema eraldatud komaga. NB! CSV failis koma järele tühik ei käi!
Küsi kasutajalt kummas formaadis ta soovib faili genereerida (tühikutega eraldatud või CSV) ning genereeri sobilik väljundfail.
Tühikutega eraldatud faili laiendiks peab olema
.txt , komadega eraldatud faili laiendiks peab olema
.csv .
Veendu, et CSV fail on korrektselt genereeritud – proovi avada või importida genereeritud faili kasutades Libreoffice Calc’i või Microsoft Office’it ja kontrolli kas väljad tuvastati korrektselt.
Lisaülesanne 2 [W07-3]: Seadistused
Selles lisaülesandes muudame oma generaatori paindlikumaks ja lisame seadistuste võimekuse.
Nõuded
Kõik seaded tuleb hoida struktuuri liikmetena – loo uus struktuuri kirjeldus seadistuste hoidmiseks
Kõigil seadistustel peavad olema vaikeväärtused
Kui kasutaja ei soovi seadistusi muuta, peab programm kasutama vaikeväärtusi. Kuidas kasutaja muutmissoovist teada peab andma, võid ise otsustada. Näiteks võib programm seda esimese asjana käivitudes küsida või saab kasutaja käivitada programmi kindla käsureaargumendiga, mis seadistuse avab.
Kasutajal peab soovi korral olema võimalik muuta järgnevaid seadistusi
Millised andmeväljad genereeritakse (iga andmevälja peab olema võimalik sisse-välja lülitada)
Väljundfaili nimi (ainult nimeosa, faililaiend valitakse automaatselt lähtuvalt valitud väljundformaadist!)
Väljundformaadi valik (lisaülesande 1 osa, tõsta struktuuri sisse)
Genereeritavate kirjete arv (baasülesande osa, tõsta struktuuri sisse)
Sisseastumispunktide vahemik (alam- ja ülempiir)
NB! Genereeritavate kirjete arvu tuleb küsida olenemata sellest, kas kasutaja soovis seadeid muuta või mitte. Eesmärk on hoida kõik seadistused vastavas struktuuris koos.
Kasutajale tuleb kuvada ülevaade genereerimisel kasutavatest seadetest. Seda olenemata kas ta soovis neid muuta või mitte.
Märkus: Soovi korral võid seadistuste väärtusi hoida eraldi failis, kuid see pole vajalik. Kasutaja tehtud muudatusi seadetesse ei ole vaja meeles pidada järgmisel programmi käivitamisel. Küll aga kui sa soovid seadefaili kasutada, siis veendu, et kasutaja saab seadistusi muuta läbi programmi (ilma, et ta peaks seadefaili käsitsi muutma).
Vihje: Siin saab kolmikoperaatorit hõlpsasti ära kasutada printf("First name: %10s\n",settings.genFirstName?"Yes":"No");
Pärast seda tundi peaksid
Oskama kasutada dünaamilist mälu
Oskama kontrollida, kas programmis on mälulekkeid
Teadma, mis olukorras on dünaamilist mälu mõistlik kasutada ja millal mitte
Teadma dünaamilise mälu võludest ja valudest
Tegema vahet pinumälul ja kuhjal ning mis muutujad kuhu lähevad.
Selles praktikumis on üks ülesanne, mis on jagatud kaheks osaks. Ülesannet laiendab kaks lisaülesannet.
NB! Kuigi arendada saad oma lahendused ükskõik mis platvormil, siis üks osa tõestusest vajab Valgrind tööriista kasutamist. Valgrind töötab kontrollitult vaid Linuxil (rakendus olemas ka MacOSil) – vajadusel saad rakenduse tõestuseks üles laadida kooliarvutisse.
Arhiiv sisaldab andmefaile nii baasülesandeks kui lisaülesandeks!
Ülesande osa 1 / 2 [W06-1]: Andmete lugemine, töötlemine
Esimeses osas on meie eesmärgiks saada programmi andmed sisse ning demonstreerida oma oskusi Makefile’i koostamiseks ja kasutamiseks ning mälus vigade puudumiseks.
Nõuded
Loe andmed sisendfailist
Andmefaili struktuur <õppeaine nimi> <hinnete arv> <hinded>
Loetud andmed salvesta struktuurimassiivi. Hinnete jaoks võid teha mõistliku pikkusega massiivi – näiteks max 20 hinnet aine kohta (lähtuvalt näitefaili struktuurist).
Kuva ekraanil
Õppeaine nimi
Õppeaines antud hinded
Õppeaine keskmine hinne
Hoia andmete lugemine, keskmise leidmine ja väljastus eraldi funktsioonides!
Kood peab olema tükeldatud vähemalt kahte koodifaili, millest mõlemal on oma päisefail. Tükeldus peab olema mõistlik, kuid on jäetud sinu otsustada.
Kood kompileeri programmiks kasutades Makefile’i
Makefile’is peab olema minimaalselt kirjeldatud retsept
all , muutuja
CFLAGS ja lipud
-Wall -Wextra -Wconversion -g -fanalyzer
Ülejäänud Makefile’i keerukuse ja ülesehituse võid ise otsustada
Kaitsmisel
Näita projekti kompileerimist kasutades Makefile’i
Näita programmi väljundit läbi Valgrindi tõestamaks, et puuduvad mäluvead.
Vihje
Hinnete arv aine kohta varieerub – st iga failis olev andmerida võib olla erineva pikkusega. Seetõttu on andmefaili võimalik lugeda ühe
fscanf() funktsiooni väljakutsega!
Lugemine on vaja teha pesastatud tsüklitega, kus
Välimine tsükkel loeb õppeaine nime ning hinnete arvu
Vastavalt välimisest tsüklist saadud hinnete arvule määratakse ära sisemise tsükli korduste arv, lugemaks sisse õppeaines antud hinded. Ära unusta sisemise tsükli
fscanf() funktsiooni tagastust kontrollida!
Testimine
Näide võimalikust koodi struktuurist.
NB! Failide nimed ei ole ette määratud, tegu on lihtsalt näidisega. Samuti piisab vaid ühest andmefailist ning see ei pea olema eraldi kaustas.
1
2
3
4
5
6
7
8
9
.
├── data
│ ├── data_grades.csv
│ └── data_grades.txt
├── analyzer.c
├── analyzer.h
├── Makefile
├── subjects_processor.c
├── subjects_processor.h
NB! Järgnevas näites ei ole kajastatud valgrindi väljundit! Ära unusta testida oma programmi korrektsust valgrindiga!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
Subject: Programming
Grades: 4 5 5 4 2 5 1 4 2 5
Average: 3.70
Subject: Databases
Grades: 5 3 3 4 4 3
Average: 3.67
Subject: Mechatronics
Grades: 3 3 4 4 5 0
Average: 3.17
Subject: Physics
Grades: 5 5 3 3 2 3 4 5 1 1 2 4
Average: 3.17
Subject: Ethics
Grades: 5 5 5 4 5 3
Average: 4.50
Subject: Scientology
Grades: N/A
Average: N/A
Subject: Chemistry
Grades: 4 4 3 4 5 4 5
Average: 4.14
Ülesande osa 2 / 2 [W06-2]: Logimine
Selle osa raames tuleb sul lisada oma programmi logimine.
Nõuded
Lisa oma programmi logimine
Üks logi rea kohta. Logi ei tohi olla kaherealine!
Iga logi rida algab ajatempliga. Ajatempel peab sisaldama kuupäeva (päev, kuu, aasta) ja kellaaega (tunnid, minutid, sekundid)
Programmi järgmine käivitus ei tohi kustutada eelneva käivituse logi
Faili lugemine lõpetatud. Logis kuva loetud ridade arv!
Faili lugemine katkestatud, kuna massiivi maksimaalne piir on ületatud (maksimaalne piir kuvatakse logis). NB! Sul on struktuuride massiiv ja struktuuri liikmena hinnete massiiv!
Viga aine keskmise hinde arvutamisel.
Logi terviklikkus peab olema garanteeritud ka programmi kokkujooksu korral
Võimalus 1: Väljundpuhvrist on võimalik sunniga andmed faili kirjutada kasutades funktsiooni
fflush()
Võimalus 2: Sulge logifail pärast kirjutamist – faili sulgemise järel kirjutatakse puhvris olevad andmed faili.
Logifaili avamise ebaõnnestumisel peab programm jätkama tööd, mitte väljuma! Teavita kasutajat logimise ebaõnnestumisest.
Vihjeid
Valmista ette logitav sõne enne logimise funktsiooni väljakutsumist! Ära koorma logimise funktsiooni üle parameetritega. Sõne ettevalmistamiseks on hea funktsioon
snprintf()
Logifunktsiooni lihtsustamiseks on soovitatav mitte failiviita ega nime sellele kaasa anda. Võimalike lahendusi:
Ava ja sulge fail logifunktsioonis järjest
See on üks võimalikest eranditest globaalmuutujale – soovi korral võid teha failiviida logifailile globaalmuutujana. (See ei ole hea lahendus, kuid aktsepteeritav – parem võimalus on kirjutatud lahti lisaülesandena).
Näiteks võiks logimise väljakutsumine välja näha nii: Logger("Program started");
Lisaülesanne 1 [W06-3]: Logimise teek
Selle ülesande raames lood sa endale logimise teegi. Vihje: seda saad ära kasutada kodutöö 2 juures!
Nõuded
Lisa programmile eraldi .c ja .h fail ja tõsta sinna logimine
Lisa 4 logimise taset – OFF, ERROR, WARNING ja INFO – need on loendi tüüpi (enum).
Iga logifaili rea juures on kirjeldatud selle logi tase.
Logi kirjutatakse faili vaid siis, kui määratud tase seda lubab. Näiteks:
INFO taseme korral kirjutatakse kõigi tasemete logid;
WARNING taseme korral kirjutatakse ainult WARNING ja ERROR tasemega logid;
ERROR taseme korral kirjutatakse ainult ERROR tasemega logid;
OFF korral logisid ei kirjutata;
Iga kutse logi kirjutamiseks peab nüüd sisaldama selle logi olulisuse taset (ERROR, WARNING või INFO)
Näiteks:
Logger(LOG_INFO, "Program started");
Teek peab toetama logi väljundfaili nime andmist
Näiteks:
LoggerSetOutputName("log.txt");
Teek peab toetama programmi logitaseme sättimist
Näiteks:
LoggerSetLoggingLevel(LOG_INFO);
Logimise seadistused tuleb hoida logimise teegi sisemiselt. Selleks on logifaili nimi ja logi tase (võid ka lisada täiendavaid). Need hoiusta logi koodifailis globaalmuutujatena.
Logifaili seadistustel peavad olema vaikeväärtused – näiteks kui kasutaja unustab või ei soovi neid seadistada, siis programm ei läheks katki.
Iga logi peab sisaldama kellaaega nii nagu oli kirjeldatud ülesande teises osas.
Käesoleva lisaülesande eesmärgiks on toetada mitmest sõnast koosnevaid õppeainete nimesid. Selleks on vaja toetada välja sees paikevat tühikut.
Nõuded
Kasuta sisendfailina CSV versiooni sisendfailist
Andmeväljad on üksteisest eraldatud komaga. Andmeväljad ise komasid ei sisalda.
Lahenduskäik
NB! Kasutame lihtsustatud metoodikat CSV lugemiseks. Sellega ei ole võimalik lugeda ükskõik missugust CSV faili! St kui andmeväli võib sisaldada ka komasid, siis seda metoodikat kasutada ei saa!
Kui vajad täielikku CSV tuge, kasuta kas vastavat teeki (nt libcsv) või kirjuta näiteks olekumasina-põhine töötlemine (loed tähemärk-haaval ja otsustad mida teha lähtuvalt loetud tähemärgist ja hetkeolekust olekumasinas)
scanf() funktsioonide perekond võimaldab lisaks andmeformaadi kirjeldamisele ka kirjeldada oodatavat sisendit ning lihtsamaid regulaaravaldisi.
Näiteks lugemaks kasutajalt kellaaega, saame kasutada formaati
scanf("%d:%d",&hours,&minutes); – sellisel juhul saab kasutaja sisestada kellaaja formaadiga
14:35 . Muutuja
hours saab väärtuseks
14 ja
minutes väärtuseks
35 . Kui aga kasutaja sisestab
14 35 , siis
hours saab ikka väärtuseks
14 , kuid kuna tühik polnud oodatud formaat, siis sealt edasi ei loeta ning
minutes jääb väärtustamata.
Lähtuvalt sellest teadmisest saame koostada faili lugemiseks formaadi
fscanf(fp, "%[^,],%d", ...) . Asenda failiviida nimi enda kasutatud viidaga ning kolme punkti asemele pane oma muutujad kuhu andmeid salvestad.
Esimene väli loetakse tekstina kuniks komani (koma ei loeta). See salvestatakse tekstimassiivi (õppeaine nimi)
Seejärel loetakse puhvrist välja koma (ja visatakse ära)
Siis loetakse sisse üks täisarv (hinnete arv aines)
Sedasi saad loetud esimesed 2 välja. Edasi pead juba formaadi koostama hinnete lugemiseks (ära komasid unusta!).
Pärast seda tundi peaksid
Teadma erinevate ehitussüsteemide kohta
Oskama koostada lihtsat Makefile’i
Teadma, kuidas deklareerida muutujaid ja neid kasutada
Teadma, kuidas koostada retsepti, sh mitut retsepti ühes failis
Teadma, mis retsepti sees käib
Teadma varjatud reeglitest ja oskama neid vajadusel kasutada
Oskama kasutada Makefile’i programmi kompileerimiseks
Oskama kasutada valgrindi programmist vigade leidmiseks ja korrektsuse kontrollimiseks
Oskama programmi siseselt hetke kellaaega leida ning seda kujundada
Esimeses ülesandes õpid sorteerima arvumassiive ning struktuuridest koosnevaid massiive ja koodi tükeldama
Teises ülesandes õpid andmeid internetist alla laadima
Mõlemat ülesannet laiendab lisaülesanne
Ülesanne 1 [W05-1]: Quicksort
Selle ülesande eesmärk on harjutada
qsort() funktsiooni kasutamist ning koodi tükeldamist erinevate koodifailide vahel, sealjuures alustad oma esimese kergesti lisatava teegifaili loomist. Aluskoodis on koodi tükeldus failidesse sinu eest juba tehtud.
NB! Aluskood sisaldab nii baasülesannet kui ka lisaülesannet!
Nõuded
Realiseeri vajalikud funktsioonid, mis on ette antud sulle erinevates päisefailides prototüüpidena. Funktsiooni realisatsioon peab olema päisefailiga samanimelises .c koodifailis
Kutsu välja vajalikud funktsioonid andmete sorteerimiseks ja ekraanile kuvamiseks main funktsiooni switch lausest.
Kompileeri programm kokku mitmest koodifailist – vastavalt struktuurile mis oli antud aluskoodis. Kasuta kompileerimiseks käsurida (võid kasutada ka Makefile’i kui oskad).
Soovitusi lahendamiseks
Tutvu arhiivis oleva koodi struktuuriga
Realiseeri alustuseks qsort võrdlusfunktsioon täisarvude võrdlemiseks. Vihje: Testimaks ühe faili põhiselt (nt array_helpers.c) kood sai korralikult kirja, võid vajutada “compile” nuppu – selle põhjal tehakse objektfail ainult käesolevast failist, ignoreerides ülejäänud programmi. Sedasi saad kiirelt vigu lokaliseerida ühe faili sees.
Lisa qsort väljakutse menüüsse, ehita kogu projekt ning proovi kas töötab
Korda sama murdarvuliste massiivi sorteerimiseks (menüü valik 2). Arvesta, et pead leidma ka murdarvudest koosneva massiivi pikkuse ning lisama väljastamise väljakutse
Nüüd liigu struktuuride juurde. Alusta struktuuri väljastamise funktsioonist. Kirjuta see valmis ning lisa väljakutse menüüsse, testi
Võrdlusfunktsiooni edastatakse
void tüüpi viidad on struktuurile endale (st struktuuri esimese baidi mäluaadress), mitte väljale, mille alusel sina soovid sorteerida TÜÜPVIGA: Teisendus peab toimuma struktuuri tüüpi viidaks, mitte int või float vms tüüpi viidaks
Miks? sorteerimisel sorteeritakse terveid struktuure korraga. qsort ise ei tea mis välja alusel sorteerimist tuleks teha ega oska seda välja valida sinu eest. Samuti järjestamise vältel tuleb ümber paigutada kõigi struktuuri liikmete andmed, mitte ainult üks alamväli.
Ole ettevaatlik sulgude paigutusega – tehete järjekord on ülioluline! Esmalt tuleb võrdlusfunktsiooni parameeter teisendada sobilikuks struktuuri tüüpi viidaks. Alles seejärel võib struktuuri sees oleva välja poole pöörduda.
3.Sort anddisplay structures ordered by employment length
4.Sort anddisplay structures ordered first name
5.Sort anddisplay structures ordered by last andfirst.
0.Exit
>1
Integerarray:
-540391517192225
Select your action!
1.Sort anddisplay integerarray(intArr)
2.Sort anddisplay floatarray(floatArr)
3.Sort anddisplay structures ordered by employment length
4.Sort anddisplay structures ordered first name
5.Sort anddisplay structures ordered by last andfirst.
0.Exit
>2
Decimal array:
11.2076.4076.5076.60235.40341.60
Select your action!
1.Sort anddisplay integerarray(intArr)
2.Sort anddisplay floatarray(floatArr)
3.Sort anddisplay structures ordered by employment length
4.Sort anddisplay structures ordered first name
5.Sort anddisplay structures ordered by last andfirst.
0.Exit
>3
Employees sorted by employment length:
Sirje Vakra15.400
Anneli Oja7.300
Doris Rebane10.203
Mark Rebane10.305
Andres Rebane22.5010
Select your action!
1.Sort anddisplay integerarray(intArr)
2.Sort anddisplay floatarray(floatArr)
3.Sort anddisplay structures ordered by employment length
4.Sort anddisplay structures ordered first name
5.Sort anddisplay structures ordered by last andfirst.
0.Exit
>4
Employees sorted by employee first name:
Andres Rebane22.5010
Anneli Oja7.300
Doris Rebane10.203
Mark Rebane10.305
Sirje Vakra15.400
Select your action!
1.Sort anddisplay integerarray(intArr)
2.Sort anddisplay floatarray(floatArr)
3.Sort anddisplay structures ordered by employment length
4.Sort anddisplay structures ordered first name
5.Sort anddisplay structures ordered by last andfirst.
0.Exit
>0
risto@risto-wk-tux:~/pr2/lab/wk5_div/t1_qsort/$
Ülesanne 2 [W05-2]: Väliste teekide kasutamine (Tallinna busside väljumised)
Selles ülesande eesmärk on näidata, et programmid saavad suhelda ka internetiga. Selleks tuleb kõigepealt programm liidestada välise teegiga libcurl, mis on laialdaselt kasutusel võimaldades suhelda APIdega, laadida faile alla jne. Ülesande lahendamiseks kasutame Tallinna Transpordiameti poolt pakutavaid avaandmeid. Lisaks peate looma ja kompileerima projekti, mis koosneb mitmest koodi- ja päisefailist.
Selle lihtsustamiseks on tehtud esialgne koodijaotus ning internetist failide allalaadimiseks ja kettale salvestamiseks vajalik kood on juba loodud. Suurem osa sellest on libcurl teegi arendajate avalik näidiskood. Kood on pakitud täiendava turvakihiga, et vältida avalike andmete kuritarvitamist, piirates seejuures värskenduste allalaadimise sagedust. Ära eemalda leech-kaitsekoodi. Andmete liiga sage küsimine toob tõenäoliselt kaasa teenusest blokeerimise.
Kirjutatud kood ja tehtud lihtsustused on loodud Linuxi jaoks. Kui soovid seda koodi Windowsis käivitada, tuleb faili käsitlemise ja tuvastamise osad koodis ümber kirjutada.
Kasuta etteantud aluskoodi ja järgi faili struktuuri
Lae alla Raja peatuse andmed
Väljasta praegune kellaaeg (kasuta peatuse andmetes olevat kellaaega)
Väljasta busside väljumisajad bussipeatusest
Minimaalselt tuleb kuvata liininumber, väljumise aeg, sihtkoht (lõpp-peatus) ja aeg bussi saabumiseni (GPS-andmete põhjal)
Lisa hilinemise hoiatus, kui buss hilineb üle ühe minuti
Ära näita busse, mis on juba väljunud
Väljumisaeg peab olema formaadis h:mm:ss
Uuenda järelejäänud aega korra sekundis
Minimaalselt peab kood olema jaotatud kolmeks koodi- ja päisefailiks
file_helper.c ja
file_helper.h sisaldavad andmete allalaadimise ja ettevalmistamise koodi (antud algkoodis olemas, muuta ei ole vaja)
data_processor.c ja
data_processor.h sisaldavad andmete lugemise ja töötlemise koodi.
main.c ja
main.h sisaldavad programmi töövoo juhtimist ja üldisi makrosid.
Soovi korral võid faili lugemise ja andmete töötlemise eraldada täiendavatesse failidesse.
Kompileeri kõik koodifailid kokku kas käsurealt või kasutades Makefile’i
Soovituslik töövoog
Samm 0: Ettevalmistus
See on vajalik ainult siis, kui kasutad enda arvutit! Kooliarvutit kasutades pole ettevalmistus vajalik!
Installi
libcurl teek. Debianil põhinevates süsteemides, sealhulgas Ubuntu ja Linux Mint, tuleb käivitada järgmine käsk:
1
sudo apt install libcurl4-openssl-dev
Teiste distributsioonide puhul, mis ei kasuta apt-i, kasuta oma distributsioonile vastavat paketihaldurit.
See paigaldab vajaliku teegi, millega C-programm suhtleb failide internetist allalaadimiseks.
Samm 1: Leia Raja peatuse ID
Peatuse ID on täisarv, mis jääb tavaliselt vahemikku 100 kuni 10 000. Enamik Tallinna peatuste ID-d jäävad vahemikku 100 kuni 2000.
Tähelepanu: Mitmel peatusel on sama nimi – nt Keemia peatusel on kaks erinevat peatuse ID-d, millest üks on suunaga kesklinna ja teine on suunaga bussiparki. Samamoodi on Raja peatusel üks peatus IT-maja ees ja teine IT-maja kõrval. Mõlemal on erinev ID väärtus.
Eeldatud on, et leiad õige peatuse ID käsitsi. Programmi abil stopid väärtuse leidmine jääb ülesande skoobist välja.
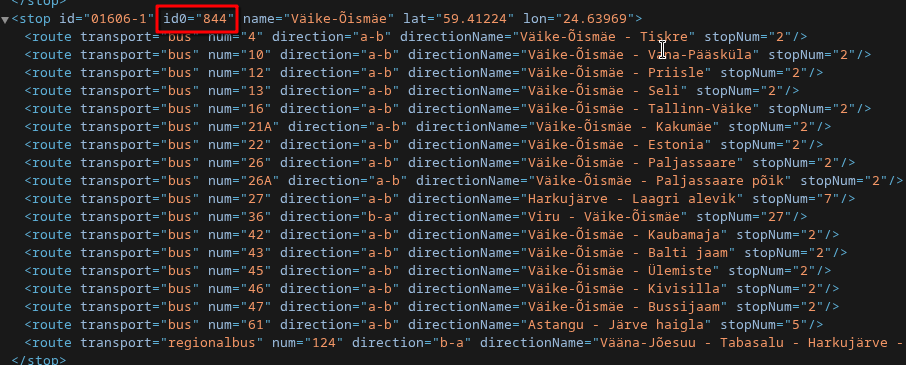
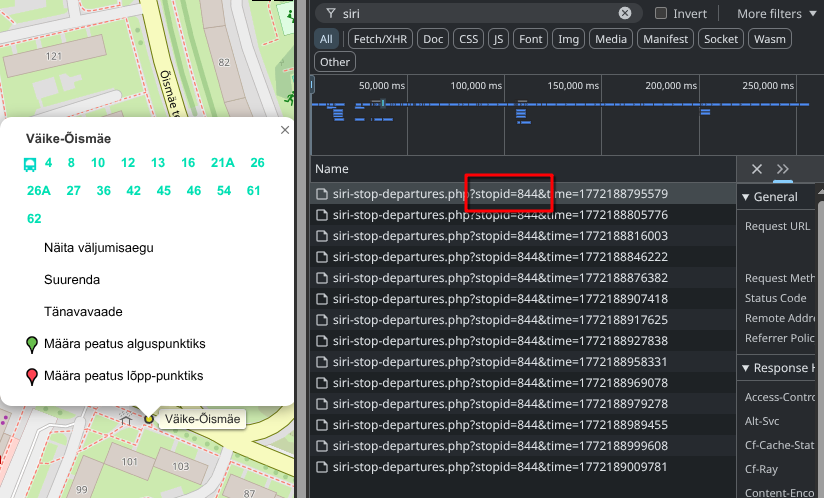
Vajaliku peatuse leidmiseks on kaks võimalust. Näidetes on toodud, kuidas leida Väike-Õismäe peatuse ID, milleks on 844.
Mine transport.tallinn.ee lehele ja ava oma brauseris arendaja tööriistad (kiirklahv F12). Seejärel ava vahekaart Network. Nüüd on sul kaks võimalust: kliki kaardil bussipeatusel ja vali väljumisaegade kuvamine; või vali sõiduplaanist buss ning klõpsa bussipeatuse nimele. Lõpuks otsi päringut nimega “siri-stop-departures” – see sisaldab parameetrit stopid=, kust leiad peatuse ID.
Samm 2: Andmefaili allalaadimine
Failide allalaadimise kood on juba valmis. Kasutame libcurl teegi dokumentatsioonist pärit näidiskoodi, millele on lisatud kaitsemehhanismid, et programm ei koormaks serverit üle, kui peaksid kogemata käivitama allalaadimisfunktsiooni liiga tihti.
Faili allalaadimiseks kutsu välja funktsioon
DownloadFileToDisk() . Funktsioon on kirjeldatud failis
file_helper.h ja implementeeritud failis
file_helper.c . Kasutusjuhised leiad päisefailist. Esimese parameetrina tuleb sul koostada URL, mis sisaldab
stopid väärtust. URL peab olema defineeritud failis
main.h .
Seejärel kompileeri programm koos kõigi kolme lähtefailiga ja käivita see. Kasuta lippu
-lcurl et linkida libcurl teek (nt
gcc -o transport_app file1.c file2.c file3.c -g -Wall -Wextra -Wconversion -lcurl ). Seejärel laetakse fail alla. Kontrolli käsitsi, et fail on kettale salvestatud (samas kataloogis, kus programm asub).
Samm 3: Andmete lugemine ja salvestamine
Failist saadud andmed tuleb lugeda struktuurimassiivi. Alusta sobiva struktuuri defineerimisest. Kõiki andmefailis olevaid välju ei ole vaja salvestada – osa neist on ülesande jaoks liiased.
Kirjuta struktuuride deklaratsioonid faili
data_processor.h . Selles failis peavad olema ka kõikide failis
data_processor.c realiseeritud funktsioonide prototüübid. Nende hulka kuulub ka andmefaili lugemise funktsioon. Vajadusel võid lisada abifunktsioone andmete eeltöötlemiseks.
Andmefaili lugemine on tavapärasest veidi keerulisem, sest fail sisaldab kahte päiserida, millele järgnevad sõidukite väljumised. Soovituslik on andmete lugemise ajal need ka ekraanile kuvada, et veenduda andmete lugemise korrektsuses.
Vihje 1: Faili kaks esimest rida sisaldavad päist, millega tuleb enne lugemistsükli algust tegeleda. Esimene rida sisaldab ajatemplit, mida saab kasutada leidmaks kui palju aega on väljumiseni jäänud. Kasuta seda arvutustes hetkeajana. See ei ole täiesti täpne, kuid piisavalt lähedane. Aja lugemiseks tühikutega eraldatud failist võid kasutada järgmist lugemislauset:
Kontrolli kindlasti tagastustatavat väärtust, et veenduda, kas andmed loeti korrektselt.
Vihje 2: Faili teine rida ei ole ülesande jaoks oluline (see kinnitab stopid väärtust). Võid selle vahele jätta, kasutades varasemalt õpitud võtteid, nt:
fscanf(fp,"%*[^\n]\n");
Seejärel jätka lugemistsükliga, mis peaks olema sulle tuttav selle semestri varasematest praktikumiülesannetest. Soovitatav on mittevajalikud väljad lugemisel vahele jätta, kasutades formaati
%*s (nagu näidatud currentTime lugemise näites).
Samm 4: Sõiduplaani väljastamine
Alustuseks väljasta sõiduplaan ühe korra. Peale kuvamist peaks programm tavapäraselt sulguma. Loo funktsioon, millele antakse parameetritena praegune aeg ja struktuur, mis sisaldab väljuvate sõidukite sõiduplaani andmeid. See peaks olema midagi sellist
Kuva kõik liininumbrid, sihtkohad, eeldatavad väljumisajad ja ajad eeldatava väljumiseni. Veendu, et väljastus oleks korrektselt vormistatud ja loetav.
Vihje 1: Failis on kaks erinevat aega – ExpectedTimeInSeconds ja ScheduleTimeInSeconds. Kasuta väljumisaja ja väljumiseni jäänud aja kuvamiseks sõiduki GPS-positsiooni põhjal antud hinnangulist aega.
Vihje 2: Kuna aega on vaja kuvatada tundides, minutites ja sekundites, kuid see on antud sekundites alates südaööst, võid oma koodi lihtsustamiseks kasutada järgmist abifunktsiooni. Võid seda kasutada ka andmete eeltöötlemisel faili lugemise ajal (kuid veendu, et jätad aja sekundite kujul alles).
Selle kasutamiseks on vaja lisada järgnev koodilõik päisefaili
1
2
3
4
5
6
7
8
9
#define MINS_IN_HOUR 60
#define SEC_IN_MIN 60
structTime
{
inthour;
intmin;
intsec;
};
Tähelepanu: UTF-8 sihtkohanimed
Ilmselt märkad, et mõned sihtkohanimed sisaldavad märke, mida ASCII-tabelis ei ole – nt Väike-Õismäe, Mustamäe, Männiku. Kui soovid vormindada väljundit vormingumäärajatega nagu
%20s , siis arvesta, et number 20 tähistab baitide arvu, mitte kuvatavate tähemärkide arvu. Seetõttu ei pruugi väljund joonduda korrektselt.
NB! Selle probleemi lahendamine ei kuulu selle ülesande skoobi hulka!
Aga kui oled huvitatud...
C23 sisaldab uusi võimalusi UTF-8 vormingus teksti töötamiseks. Ka vanemad C-keele versioonid toetavad UTF-8 kodeeringut, kuid nende tugi on mõnevõrra kohmakam. Tavaliselt käsitletakse seda mitmebaidiste märkide (multibyte characters) abil. See on korrektne ja robustne lahendus ning tõenäoliselt esimene vastus, mille keelemudelid lahendust küsides pakuvad. Kuid meie eesmärgi jaoks oleks see tarbetult keeruline.
On olemas ka lihtsam / häkk-lahendus ilma mitmebaidiste märkide keerukuseta. Me teame, et andmetes ei esine kolme ega nelja-baidiseid märke. Vaadates UTF-8 standardit näeme, et 2-baidise tähemärgi esimese baidi kolm esimest bitti on fikseeritud (vt 2-baidise märgi esimene bait: https://en.wikipedia.org/wiki/UTF-8#Description). Kasutades bitimaske saame kontrollida kolme esimese biti sisu. Järgnevat koodilõiku saab professionaalsemalt kirjutada kasutades viitasid tähemärgile ja 16-süsteemis kodeeritud konstanti, kuid jätan järgneva lahenduse lihtsamini (otsemini) loetavaks.
1
2
3
4
5
6
7
// Count 2-byte UTF-8 characters in printable string for extra padding
intwideChars=0;
for(inti=0;destination[i]!='\0';i++)
{
if((destination[i]&0b11100000)==0b11000000)
wideChars++;
}
Nüüd võime
printf("%20s", ...) asemel kasutada
printf("%*s", 20 + wideChars, ...) . See arvestab lisabaitidega, mida on vaja märkide korrektseks kuvamiseks.
Samm 5: Sõiduplaani uuendamine
Sõiduplaani tuleb värskendada ühe korra sekundis. Viivituse tekitamiseks kasuta funktsiooni
sleep() teegist
unistd.h .
Teiseks tuleb enne iga uut väljatrükki ekraan puhastada. Selleks kasutatakse ANSI escape jada (escape sequence). See on eelistatum lahendus võrreldes
system() funktsiooni väljakutsetega, mida internetist sageli soovitatakse. Jada sisaldab käske ekraani puhastamiseks (
[2J ) ja kursori liigutamiseks vasakusse ülanurka (
[1;1H ).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
while(1)
{
// ANSI escape sequences to clear the terminal
printf("\033[2J\033[1;1H");
// TODO: Header before the timetable
printf();
// TODO: Print the timetable
PrintTimeTable();
// TODO: Update current time by 1 second
// Next update in 1 second
sleep(1);
}
Vihje: Allalaetud failist saadud hetkeaeg on antud sekundites alates keskööst. Kui suurendad seda muutujat iga tsükli läbimisega ühe võrra, saad selle anda funktsioonile
PrintTimeTable() kaasa. Sel juhul piisab järelejäänud aja kuvamiseks sellest, kui lahutad eeldatavast väljumisajast praeguse aja.
NB! Tegemist on lõpmatu tsükliga, millel puudub lõputingimus! Korrektne programmi lõpetamine ei kuulu selle ülesande skoopi. Programmi peatamiseks kasuta Ctrl + C.
Aga kui oled huvitatud...
Selle käsitlemiseks on kaks (kolm) levinud viisi
Kasuta lõimesid (thread), mis kuulab klaviatuurisisendeid ja võimaldab sellel lõimel seada muutuja, mis tagab tsüklist väljumise. See on mõnevõrra keeruline lahendus.
Kasuta katkestussignaalide käsitlejaid (signal handlers, intterupt handler). Selleks on vaja luua globaalne volatile tüüpi muutuja, mida juhib sinu loodud signaalikäitleja (funktsioon). Muutuja kontrollimisel tsükli vältel saad tsükli katkestada. Signaalikäitleja tuleb rakenduses registreerida. Tegu on lihtsaima võimaliku loogikaga. Programmi sulgemine toimuks endiselt klahvikombinatsiooniga ctrl + c, kuid väljumine oleks korrektne. See on soovitatav viis, kui tahad proovida.
Viimaks on võimalik ka terminali töörežiimi ümber seadistada interaktiivseks kasutuseks, kuid see on märksa keerulisem ja valesti käsitlemisel veelgi veaohtlikum.
Interaktiivsed programmid kasutavad sageli teeke, mis toetuvad nendele funktsioonidele, näiteks ncurses.
Testimine
Testimiseks kasuta esmalt Raja peatust. Seda on ka lihtne kontrollida, sest saad aknast välja vaadata ja veenduda, kas buss saabus siis, kui sinu programm seda väidab.
Piirjuhtude testimine on siin keeruline, sest kasutad reaalaja liiklusandmeid ning kõiki olukordi ei pruugi alati ette tulla.
Kasuta populaarsemat bussipeatust, et testida erijuhte. Näiteks kasutasin peatust Taksopark (ID 1135). Seal on võimalik näha
Hilinemisi
Olukordi, kus järelejäänud aeg on ainult sekundites
Väljunud bussi eemaldamist nimekirjast
Sihtkohti, mis sisaldavad mitte-ASCII märke – nt Männiku, Tallinn-Väike
Pane tähele, et kõike ei ole testitud
Peatused, kus on ka trammi- või trolliliinid (trollid on saadaval loomulikult alles 2027 versioonis)
Kuidas käsitletakse järelejäänud aega busside puhul, mis saabuvad pärast südaööd, kui praegune aeg on veel enne südaööd.
Kui ühtegi bussi ei ole tulemas
MS Windows
Antud ülesannet on võimalik lahendada ka Windowsil, kuid selleks tuleb teha mõned täiendavad liigutused. Sammud on testitud ja töötasid kevadel 2022 kasutades chocolatey kaudu installeeritud 64 bitist MinGW-d (see oli osa lihtsast tarkvara paigaldamise juhendist Windowsil kasutades käsurida). Väljavõte eelmise aasta vestlusest, kus sammud kirja said (inglise keeles)
1. Install libcurl on Windows. Uses chocolatey package manager
choco install curl
2. Make the library (dll file) available to the compiled program. Copy libcurl-x64.dll from libcurl installation directory to your program directory (assumes 64-bit compiler).
3. You need to download CA certificate so cURL can verify the certificate on the opendata website https://curl.se/ca/cacert.pem.
4. You need to specify the certificate authority file location to the code. Add this to the setup of the download in the file_helper.c, replacing the path\\to\\file with the path to the downloaded .pem file.
5. You need to rewrite the check if a file is already downloaded because that uses POSIX library available on UNIX systems – unistd.h. You should rewrite it with windows solution of that. Haven’t tested, but you’ll likely find the function BOOL FileExists(LPCTSTR szPath) in the library io.h. You may need to add additional Windows-specific libraries.
6. You can only download as CSV with the code provided. To download space delimited, you need to rewrite the ReplaceChars function. Easy option would be to open up a second file pointer for writing to a different file and remove the fseek, Simplest would be to do getchar -> putchar with a check in between for commas to be replaced with spaces.
7. You need to add -I and -L flags to your compiler command line arguments. Mine were:
Lisaülesanne 1 [W05-3]: Mitme struktuuri liikme põhjal sorteerimine
Lisaülesande lahendamiseks peab olema realiseeritud menüü valik 5 jaoks vajaminev funktsionaalsus. Selleks pead:
Realiseerima qsort võrdlusfunktsioonid struktuurimassiivi sorteerimiseks perenime järgi. Kui perenimed on samad, tuleb teha täiendav otsus sorteerimiseks eesnime alusel.
Kutsuma välja qsort funktsiooni struktuurimassiivi sorteerimiseks vastavalt menüü valikule ning seejärel massiivi väljatrüki funktsiooni
Kutsuma välja qsort funktsiooni struktuurimassiivi sorteerimiseks vastavalt menüü valikule ning seejärel massiivi väljatrüki funktsiooni
Testimine
Järgnev väljund sisaldab vaid lisaülesande tulemust
Lisaülesande lahendamiseks pead alla laadima ka teise andmefaili, mis sisaldab kõigi sõidukite GPS asukohakordinaate.
Lae GPS asukohti alla perioodiliselt. Aadressi leiad samuti arendaja tööriistu kasutades või avaandmete portaalist. Soovitav andmete uuendamisintervall on 5 .. 10 sekundit
Leia ICT hoone asukohakordinaadid
Arvuta kõigi sõidukite kaugus ICT hoonest
Järjesta sõidukid kauguse järgi kasvavas järjekorras
Uuenda väljundit perioodiliselt.
Piira väljudnite arvu nii, et nii baas- kui lisaülesande väljundid mahuksid mõistlikult ekraanile
NB! Uuendamise intervalli miinimumaeg on 15 sekundit, mis on antud aluskoodiga kaasa. Muuda see lühemaks, et võimaldada asukohti tihedamalt alla laadida.
Testimine
Märka, et videos uuendatakse asukohakordinaate ning kaugust hoonest ligikaudu iga 5 sekundi tagant. Kõigi sõidukite asukohad ei muutu – näiteks osad võivad parasjagu paikneda lõppjaamas, oodates oma väljumisaega.
Vihjed
Kauguse leidmiseks kahe punkti vahel maakeral on mitmeid valemeid. Haversine on üks võimalikest – see pole küll kõige täpsem, kuid on võrdlemisi lihtne ja arvutuslikult kiire.
Soovitav on tehta loendur, mis “tiksub” nagu kell, et käivitada perioodiliselt andmefaili allalaadimine ja töötlemine
Kui soovid kauakestvat ja täpsemat programmi, saad uuendamist rakendada ka väljuvatele sõidukitele
Pärast seda tundi peaksid
Oskama tükeldada oma programmi mitme koodifaili vahel mitmest koodifailist koosnevat programmi kompileerida
Oskama kasutada qsort funktsiooni
Mõistma qsort funktsiooni võrdlusfunktsiooni nõudeid ning suutma kirjutada võrdlusfunktsiooni lihtsatele massiividele ning ka struktuurimassiividele
Teadma viitade eksisteerimisest funktsioonidele ning oskama funktsiooni edastada viita teisele funktsioonile
Teadma üldistatult samme, mis on vajalikud kolmandate osapoolte teekide kasutamiseks ning oskama neid oma programmi kompileerida
Praktikumi vältel lahendad ülesande, mis on tükeldatud kaheks hinnatavaks osaks. Esimese osa fookus on andmete lugemine ja seostatult väljastamine ning teises osas teed arvutusi üle seostatud andmete, sh lisad struktuurile täiendavaid alamvälju mida failis ei eksisteeri. Ülesande raames õpid ka päisefaile kasutama.
Ülesande 1. osa [W04-1]: Seostatud andmete väljastamine
Selles osas trükime välja failidest loetud andmed. Selleks on oluline õigel hetkel teha vajalikud seostamised kahe struktuuri vahel.
Andmefailid
Andmed on sulle antud kahes eraldi failis, mille kirjeldamiseks kasutame olemi-suhte diagrammi (ERD ehk entity-relationship diagram).
NB! Selliseid suhteid näidatakse sageli ka UMLi klassidiagrammina. Vaata all viidet selle kohta!
Olemi-suhte diagrammi kardinaalsus
Ühel isikul võib olla 0 või enam sõidukit
Iga sõiduk peab kuuluma täpselt ühele isikule
Andmed kahes failis on seostatud Eesti isikukoodi (person_id) abil.
Teises osas kirjutame laienduse esimesele osale. Kõik esimeses osas olnud nõuded kehtivad ka siin.
Nõuded
Leia ja kuva palju iga omanik makse maksma peab
Kuvada tuleb nii summa kui protsendina sissetulekust
Lisa hoiatus, kui maksud ületavad 10% isiku aastasest sissetulekust.
Väljasta veateade, kui inimesel puuduvad sissetuleku kohta andmed.
NB! Meenuta, et funktsioonid peaksid vaid ühte asja tegema. Ära pane arvutamist samase funktsiooni, kus andmeid väljastad või faile loed! Tee eraldi funktsioon maksude leidmiseks.
Vihje: Lisa struktuuri täiendav liige või liikmed, et saaksid hoiustada ja kuvada maksuandmeid. Struktuuri liikmed ei pea olema 1:1 vastavuses sellega, mis on hoiustatud failis, täiendavate väljade lisamine või isegi andmete töötlemine ja teises formaadis hoidmine mälus on OK.
Soovituslikud funktsioonid
NB! Tegu on soovitusliku loeteluga. Sinu loodavad funktsioonid ning nende parameetrid võivad sellest erineda.
Praktikumis lahendatakse kommenteeritult koos läbi failist struktuuridesse lugemise näide. Neile, kes praktikumis ei osalenud, on see avaldatud koodinäitena: Failist struktuurimassiivi lugemise näide
Praktikumi ülesanded
Selles praktikumis on üks ülesanne, mida laiendab kolm lisaülesannet.
Ülesanne [W03-1]: Töötajate otsing
Ülesande eesmärgiks on õppida struktuure kasutama. Ülesanne ise matkib töötajate andmebaasi, kust on võimalik filtreerida töötajate andmeid vastavalt etteantud otsinguparameetrile.
Andmefail koosneb juhugeneraatoriga loodud andmetest.
Nõuded
Loe failist ettevõtte töötajate andmed
Korduv faili lugemine programmi sees ei ole lubatud.
Failis on iga rea kohta üks kirje
Iga andmeväli on eraldatud tühikuga. Andmeväljad on ühesõnalised.
Andmete struktuur failis <eID> <first_name> <last_name> <city>
Programmis tuleb andmeid hoida struktuuridest koosnevas massiivis.
Programm peab töötama olukorras, kus andmete täpne arv pole teada ning see võib ajas muutuda (näiteks värvatakse uus töötaja, senine töötaja lahkub).
Loo programmile mõistlik limiit ning veendu, et sellest üle ei mindaks!
Kui andmefailis on rohkem andmeid kui mahub, väljasta vastav hoiatus.
Programm peab lubama käskude ja otsingute korduvat tegemist ilma taaskäivitamata
Luba programmi kasutajal teostada otsingut linna nime järgi
Programm väljastab kõik töötajad, kes sisestatud linnas elavad
Näita mitu vastet mitmest leiti (nt [0 / 91])
Otsingut peab saama sooritada korduvalt ilma programmist väljumata
Baasülesandes väljasta kõik andmed – isikukood, perenimi, eesnimi, linn
Programm peab toetama käskude töötlemist
Käsud algavad kooloniga – sedasi tuleb eristada kas sisestati käsk või otsisõna
Käsuga “:all” väljastatakse kõigi isikute loetelu
Käsuga “:exit” sulgetakse programm
Vihjed
Käskude töötlemine võib kõlada hirmutavalt, kuid tegelikult on lahendus väga primitiivne. Kõike seda õppisid juba Programmeerimine 1 sõnede tunnis. Kokku on vaja teha 3 sammu:
Tuvasta, kas kasutaja sisestas käsu – kontrolli kas 0-nda indeksi peal on kooloni sümbol. See oli ka üks näidetest sügisel.
Loo viit, mis näitab teise tähemärgi aadressile (
char*command=input+1; ) – see on viidaaritmeetika esimesest nädalast, mida kasutasid ka eelmine nädal faili laiendi asukoha määramiseks.
Võrdle sisestatud käsku toetatud käskudega.
Programmi näidisväljund
Esimeses näites vaatame käsu töötlemist. Kui käsku ei tuvastata, antakse vastav veateade. Kui käsk sisestatakse ilma eelneva koolonita, teostatakse hoopis linna nime järgi otsing (vaikimisi käitumine).
Pane tähele, et
:all käsu näite jätsime vahele – see läheks liialt pikaks.
Viimases näites näed programmi väljundit, kui kõik lisaülesanded on tehtud. Väljud on pikk, seega pead selle käsitsi lahti klikkima.
Kliki mind, et näha väljundit
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
risto@risto-lt:~/pr2/wk3_struct1$ ./task_extra 03_data_short.txt Available commands
:exit | close the program
:all | print everyone in the database
:list | print list of cities
Enter a city name to search or a command
> sindi
Searching for: sindi
Saar, Anne
City: Sindi
Sex: Male
Date of birth: 1. December 1991
Mitt, Keit
City: Sindi
Sex: Male
Date of birth: 28. December 1980
Kallas, Ivari
City: Sindi
Sex: Female
Date of birth: 4. July 2001
Employees listed [3/150]
Available commands
:exit | close the program
:all | print everyone in the database
:list | print list of cities
Enter a city name to search or a command
> :list
List of cities:
Abja-Paluoja
Abjaku
Antsla
Elva
Haapsalu
Kallaste
Karksi
Karksi-Nuia
Kehra
Keila
Kunda
Kuressaare
Lihula
Loksa
Maardu
Mustvee
Narva
Paide
Paldiski
Rakvere
Rapla
Saue
Sindi
Suure-Jaani
Suure-Kambja
Suure-Rakke
Suure-Rootsi
Suurekivi
Suuremetsa
Suurepsi
Suuresadama
Suuresta
Tallinn
Tamsalu
Tapa
Tartu
Valga
Viljandi
Available commands
:exit | close the program
:all | print everyone in the database
:list | print list of cities
Enter a city name to search or a command
> ALL
Searching for: all
Michal, Peeter
City: Tallinn
Sex: Female
Date of birth: 10. May 2003
Saks, Meelis
City: Kallaste
Sex: Female
Date of birth: 2. December 1943
Toom, Aivar
City: Kallaste
Sex: Female
Date of birth: 8. March 1963
Puusepp, Anneli
City: Tallinn
Sex: Male
Date of birth: 12. July 1963
Roos, Arvo
City: Tallinn
Sex: Female
Date of birth: 27. November 1974
Hein, Jelena
City: Kallaste
Sex: Male
Date of birth: 2. November 2000
Ratas, Olga
City: Kallaste
Sex: Male
Date of birth: 1. October 1982
Tomson, Mailis
City: Tallinn
Sex: Male
Date of birth: 7. August 1969
Employees listed [8/150]
Available commands
:exit | close the program
:all | print everyone in the database
:list | print list of cities
Enter a city name to search or a command
> :exit
Lisaülesanne 1 [W03-2]: Linnade nimistu
Nõuded
Linnade nimistu kuvamiseks lisa menüüsse käsk “:list”
Kuva kasutajale kõik failis olevad linnad
Linnade nimistu peab olema järjestatud tähestiku alusel
Linnade nimekiri koostatakse programmi poolt töö ajal, vastavalt sisendfailis esinevatele linna nimedele
Linnade nimekirja peab saama kuvada korduvalt
Linnade nimekirja tohib koostada programmi töö vältel vaid ühe korra.
Lisaülesanne 2 [W03-3]: Mugavam otsing
Nõuded
Otsing ei tohi olla tõstutundlik. Näiteks otsides linna
TALLINN või
tallinn , tuleb kuvada kõik töötajad, kes elavad Tallinnas.
Otsing peab toetama osalist vastet. Näiteks otsides
all leitakse nii need, kes elavad Kallastel, kui ka need, kes elavad Tallinnas.
Mõlemad peavad töötama ka korraga. St eelnev tulemus peab olema leitav ka otsides
ALL või
aLL. NB! Märka, et
:all on käsklus kõigi töötajate kuvamiseks ning
ALL on otsing, mille tulemusena leitakse andmefailist töötajad Tallinnas ja Kallastel.
Vajuta mind, et näha selgitusi kuupäeva ja kellaaja vormingu kohta
m – Minutid vahemikus 0 – 59.
mm – Minutid vahemikus 00 – 59. Minutitele 0 – 9 lisatakse ette number null.
h – Tunnid vahemikus 1 – 12.
hh – Tunnid vahemikus 01 to 12. Tundidele 1 – 9 lisatakse ette number null.
H – Tunnid vahemikus 0 – 23
HH – Tunnid vahemikus 00 – 23. Tundidele 0 – 9 lisatakse ette number null.
d – Päevad vahemikus 1 – 31
dd – Päevad vahemikus 01 – 31. Päevadele 1 – 9 lisatakse ette number null.
ddd – Päevad lühinimega ( E / Mon; T / Tue; K / Wed; …)
dddd – Päevad täispika nimega (esmaspäev / Monday; teisipäev / Tuesday; kolmapäev / Wednesday; …)
M – Kuud vahemikus 1 – 12
MM – Kuud vahemikus 01 – 12. Kuudele 1 – 9 lisatakse ette number null.
MMM – Kuu lühinimi (jaan / Jan; veebr / Feb; märts / Mar; apr / Apr; …)
MMMM – Kuu täispika nimega (jaanuar / January; veebruar / February; Märts / March; …)
y – Aasta vahemikus 0 – 99
yy – Aasta vahemikus 00 – 99
yyy – Aasta, minimaalselt kolme numbriga (1 -> 001; 15 -> 015; 145 -> 145; 1949 -> 1949)
yyyy – Aasta nelja numbriga
Pärast seda tundi peaksid
Teadma, kuidas deklareerida uusi struktuure – st uus andmetüüp, milleks on struktuur
Oskama valida struktuuri liikmeid
Teadma, mis on struktuuri polsterdamine ja joondamine ning kuidas see mõjutab struktuuri suurust mälus
Teadma, mis mõjutab struktuuri suurust
Teadma, millised operaatorid on kasutusel struktuuri liikmete poole pöördumiseks ja oskama kasutada punkt-operaatorit
Teadma, kuidas luua struktuuridest koosnevat massiivi ja lugeda andmeid failist struktuurimassiivi
Teadma, kuidas omistada terviklikku struktuuri
Teadma, kuidas defineerida andmetüüpe ümber, andes neile uue nime (typedef)